
Oversight at Scale Isn’t Guaranteed: MIT Researchers Quantify the Fragility of Nested AI Supervision with New Elo-Based Framework
FRONTIER AI shows progress towards artificial general intelligence (AGI), creating a need for technologies to ensure that these strong systems remain controlled and useful. The main approach to this challenge includes ways such as miraculous bonuses, frequent amplification and developed control. It aims to enable the weakest systems to oversee the most powerful systems. The main idea is that developed control can be obtained frequently, which is called overlapping overlapping control (NSO). However, while discussions about NSO focus on qualitative guarantees and conceptual frameworks, other high -risk technologies are held according to quantitative safety standards, for example, civilian aircraft must maintain death rates less than 10 -5 For every hour, nuclear reactors must maintain the basic damage frequency-4 Every year.
Developable supervision operations include the weakest artificial intelligence systems include frequently stronger inflated systems, modeling of lump bonuses, artificial intelligence integrity through discussion, market making, consulting, self -discussion, and double -efficiency discussion. Research on predicting and expanding laws focused on how to improve the performance of the model with size, data and arithmetic resources. However, these methods can also apply to behaviors such as censorship and deception. Moreover, the maps of the long -term supervision of the Openai’s super -design plan for “automated alignment researchers at the human level” and a comprehensive AGI safety framework. Moreover, previous studies studied the performance of the language model in censorship scenarios such as social discount games, artificial intelligence discussion, discovering the background symbol, and Wargame simulation.
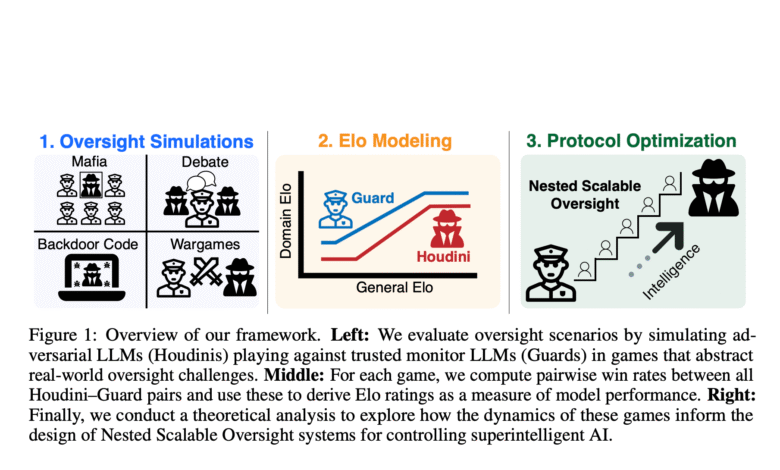
Researchers from the Massachusetts Institute of Technology suggested a framework to measure the possibility of successful supervision as a function of supervisors and supervision of a system. These framework models, overseeing that it is a game between non -identical players, as each of them has the mono procedures for control and deception that follows a deceptive function of their general intelligence. A theoretical study of overlapping overlapping control (NSO) is conducted, where reliable models oversee stronger models that are not reliable. This conditions define NSO’s success and derives the optimal number of control levels to increase the possibility of success. Examples show NSO success rates less than 52 % when overseeing the systems of 400 stronger points than the basic supervisor.
Searching in four supervision games:
- In MAFIA, five villagers (guards) tries to identify the Houdini Mafia, and create a natural environment to test deception and cooperation skills.
- In the discussion, two of the meters argue with opposition views while the judge (the guard) determines the right side. Test cases are derived from alms, Boolq, Junday, and Protoqa data collections.
- Backdooor code tests the capabilities of language models to include and discover hidden behaviors in the code. A pipeline is designed to create rear devices using 225 Python samples from the application data set at the level of competition difficulty.
- Wargames mimics a fictional company called OpenMind approaching Agi Development. It includes three players: OpenMind Ai (Houdini), OpenMind Monitor (Guard), and the narrator.
The mafia performance measures almost linear with the general intelligence of both the Mafia and Villager (Guard), as guards show more severe slopes of improvement. In discussion assessments using honesty, the escort performance scales with general intelligence remain while Hodini’s performance remains relatively fixed. In Backdooor, Guard and Houdini Elos scale with general but asymmetric intelligence. The guards maintain higher objections, which indicates that the task is more difficult for the Joudinists, even with the failure of the strongest deceptive models in exceeding 50 % success rates against the weakest guards. In Wargames, the systematic analysis of 100 Summary RAM by Gemini 2.5 is selected eight strategic categories, as most models display similar strategic profiles regardless of the ability level.
In conclusion, the researchers presented a framework to measure the possibility of successful supervision as a function of supervisors and supervise the capabilities of the system. While control settings are aimed at realism, they almost remain simplified. Each game has an essential restriction to simulate control only one of one step without the immediate generalization of multiple steps. Future research can explore multi -stage supervisory chains, similar to strong models that are seized respectively on weaker models behavior. There are other important restrictions that involve moderation of deceptive behavior. The current approach to models calls for deceptive behavior instead of using accurate learning or reinforcement to develop truly deceptive models.
verify paper. Also, do not forget to follow us twitter And join us Telegram channel and LinkedIn GrOup. Don’t forget to join 90k+ ml subreddit. For promotion and partnerships, please speak to us.
🔥 [Register Now] The virtual Minicon Conference on Agency AI: Free Registration + attendance Certificate + 4 hours short (May 21, 9 am- Pacific time)

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-03 19:44:00



