
QwenLong-L1 solves long-context reasoning challenge that stumps current LLMs

Join daily and weekly newsletters to obtain the latest updates and exclusive content to cover the leading artificial intelligence in the industry. Learn more
Alibaba Group Qwenlong-L1 has introduced, a new frame that enables LLMS models of the mind at very long inputs. This development can open a new wave of institutions that require models to understand and visions of wide documents such as detailed companies ’files, long financial statements or complex legal contracts.
The challenge of long thinking about artificial intelligence
Modern developments in large thinking models (LRMS), especially through reinforcement learning (RL), has significantly improving problem -solving capabilities. Research indicates that when trained with RL Fine Tuning, LRMS acquires similar skills for human “slow thinking”, as they develop advanced strategies to address complex tasks.
However, these improvements are seen primarily when models work with relatively short parts of the text, usually about 4000 symbols. The ability of these models to expand their thinking to much longer contexts (for example, 120,000 symbols) is still a major challenge. This long -form logic requires a strong understanding of the entire context and the ability to perform a multi -step analysis. “This restriction is a major obstacle to practical applications that require interaction with external knowledge, such as deep search, as LRMS must collect information and process it from densely knowledgeable environments,” writes QWenlong-L1 in their paper.
Researchers bear these challenges in the concept of “long thinking in the context RL”. Contrary to short thinking in the context, which often depends on the knowledge that is already stored within the model, a long -context logic requires models to recover the relevant information from the long inputs accurately. Only then can create chains of thinking based on this integrated information.
Training forms for this purpose through RL is difficult and often leads to unstable learning and improvement. Models are struggling to converge in good solutions or lose their ability to explore various thinking paths.
Qwenlong-L1: a multi-stage approach
QWENLONG-L1 is a framework for reinforcing designer to help LRMS to move from efficiency with short texts to strong generalization across long contexts. The LRMS frame in the short context is enhanced by a carefully and multi -stage organized process:
SFT: SFT: SFT: The model is first subject to SFT, where it is trained on examples of long -context thinking. This stage creates a solid basis, enabling the form of information accurately of long inputs. It helps in developing basic capabilities in understanding the context, generating logical thinking chains, and extracting answers.
RL directed to RL curriculum: At this stage, the model is trained in multiple stages, with the gradually increased length of the entry documents. This systematic approach step -by -step helps consistently adapt from thinking strategies from shorter to gradually longer contexts. It avoids instability often when the models are suddenly trained on very long texts.
A sample of difficulty retroactively: The final training phase includes difficult examples of previous training stages, ensuring that the model continues to learn one of the most difficult problems. This gives priority to difficult situations and encourages the model to explore the most diverse and complex thinking paths.
Besides this organized training, Qwenlong-L1 also uses a premium bonus system. While training on short thinking tasks in the context, it often depends on strict bases based on the rules (for example, the correct answer to mathematics problem), QWENLONG-L1 uses a hybrid bonus mechanism. This combines the rules-based verification, which ensures accuracy by verifying strict commitment to right standards, with “LLM-AA-A-Defection”. The judge’s model compares this semantic to the answer created with the basic truth, allowing more flexibility and dealing better with various methods. Correct answers can be expressed when dealing with long, accurate documents.
QWENLONG-L1 mode on the test
The Alibaba team evaluated QWenlong-L1 assessing the answer to document questions (Dorqa) as a basic task. This scenario is closely related to the needs of institutions, as artificial intelligence must understand the dense documents to answer complex questions.
Experimental results through seven long standards in the two contexts showed the capabilities of QWenlong-L1. It is worth noting that the Qwenlong-L1-32B (based on Deepek-R1-Distill-Swen-32B) achieved a similar performance of the Sonnet thinker from Anthropic-3.7, and models such as Openai’s O3-MINI and QWEN3-235b-A2B. The QWENLONG-L1-14B also exceeds the smaller GEMINI 2.0 Flash from Google and QWEN3-32B.
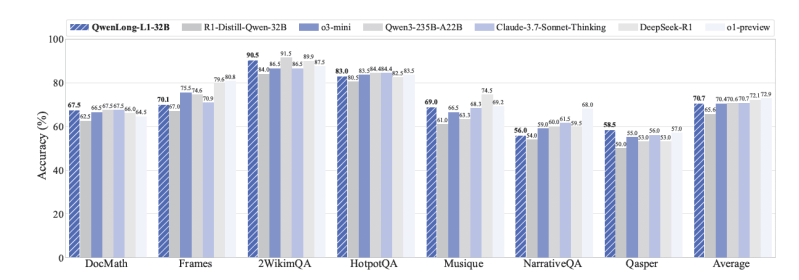
An important output result in the real world applications is how RL training in the model is the development of long -context thinking behaviors. The paper indicates that the models that were trained with Qwenlong-L1 become better in “grounding” (linking answers to specific parts of the document), “sub-preparation” (shattering of complex questions), “retreat” (identifying their mistakes and correcting them in the middle of the show), and “verification” (double verification their answers).
For example, although the basic model may be distributed through unrelated details in a financial document or was suspended in an unrelated information episode of excessive analysis, the model trained on Qwenlong-L1 showed the ability to engage in effective self-reflection. It can successfully liquidate these behavior details, back away from incorrect paths, and access the correct answer.
Techniques such as Qwenlong-L1 can greatly expand the benefit of artificial intelligence in the institution. Possible applications include legal technology (analysis of thousands of pages of legal documents), financing (deep research on annual reports and financial files for risk assessment or investment opportunities) and customer service (analysis of the long customer interaction history to provide more enlightening support). The researchers released the qwenlong-L1 recipe and weights of trained models.

Don’t miss more hot News like this! Click here to discover the latest in Technology news!
2025-05-30 23:39:00



