This AI Paper from Alibaba Introduces Lumos-1: A Unified Autoregressive Video Generator Leveraging MM-RoPE and AR-DF for Efficient Spatiotemporal Modeling
Automatic video generation is a fast -developing search field. It focuses on synthesis of videos one frame by one using the patterns learned for both spatial arrangements and timetables. Unlike traditional video creation methods, which may depend on pre -built tires or hand -made transformations, automatic models aim to create dynamic content based on symbols before. This approach is similar to the extent to which language models expect the following word. It provides the ability to unify video generation, image and messages under a joint frame using the structural strength of the transformer -based structure.
One of the main problems in this field is how to capture and design the essential spatial temporal dependencies accurately in videos. Videos contain rich structures over time and space. The coding of this complexity is still so that the models can predict the coherent future frameworks. When these dependencies are not well designed, they lead to a broken frame or generate unrealistic content. Traditional training techniques such as indiscriminate mask also struggle. They often fail to provide balanced tires. When spatial information leaks from adjacent frames, the prediction becomes very easy.
 AI-Paper-from-Alibaba-Introduces-Lumos-1-A-Unified-Autoregressive.png" alt="" style="width:862px;height:auto"/>
AI-Paper-from-Alibaba-Introduces-Lumos-1-A-Unified-Autoregressive.png" alt="" style="width:862px;height:auto"/>Several ways to address this challenge are tried by adapting the automatic generation pipeline. However, they often deviate from standard large language model structures. Some use pre -trained external textual symbols, making models more complicated and less coherent. Others bring a large transition time during the generation with ineffective decoding. Automatic models such as Phenaki and EMU3 are trying to support the comprehensive generation. Nevertheless, they are still struggling with the consistency of performance and high training costs. Techniques such as scanning arrangement or global sequence attention do not expand well to high -dimensional video data.
The research team was presented by the Damo Academy of Alibaba Group, HUPAN, and Zhejiang Lumos-1 University. It is a unified model for automatic video generation that remains correct in the structure of the big language model. Unlike the previous tools, Lumos-1 eliminates the need for external encryption and very little in the original LLM design. The MM rope, or multimedia rolling, uses, to face the challenge of designing 3D video structure. The model also uses symbolic dependency approach. This maintains the dual -direction within the frame and the time causal between the frame, which naturally corresponds to how video data is behaved.
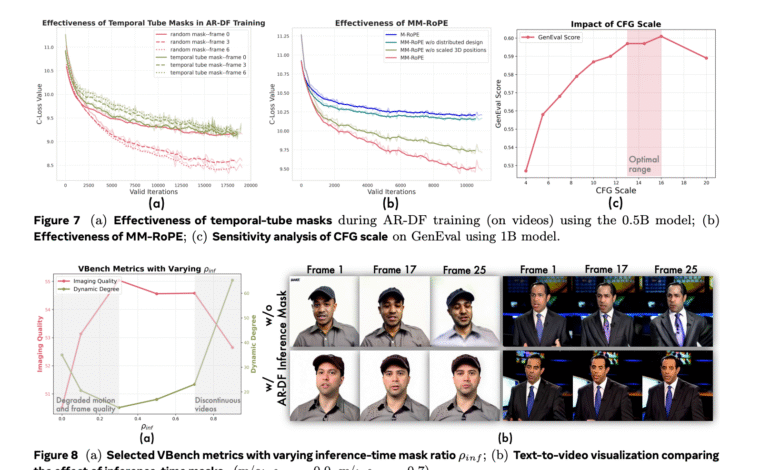
In the MM rope, researchers expand the current rope methods to balance the frequency spectrum of spatial dimensions and time. Traditional three -dimensional rope offends the frequency concentration, causing the loss of mysterious localization or coding. Restructuring the MM rope so that both time, length and width receive a balanced representation. To address the imbalance in the framework training, Lumos-1 AR-DF offers, or forcing automatic separate spread. The hide of the timber is used during training, so the model does not depend much on unconvincing spatial information. This guarantees even learning via video sequence. The inference strategy reflects training, allowing the generation of high -quality frame without deterioration.
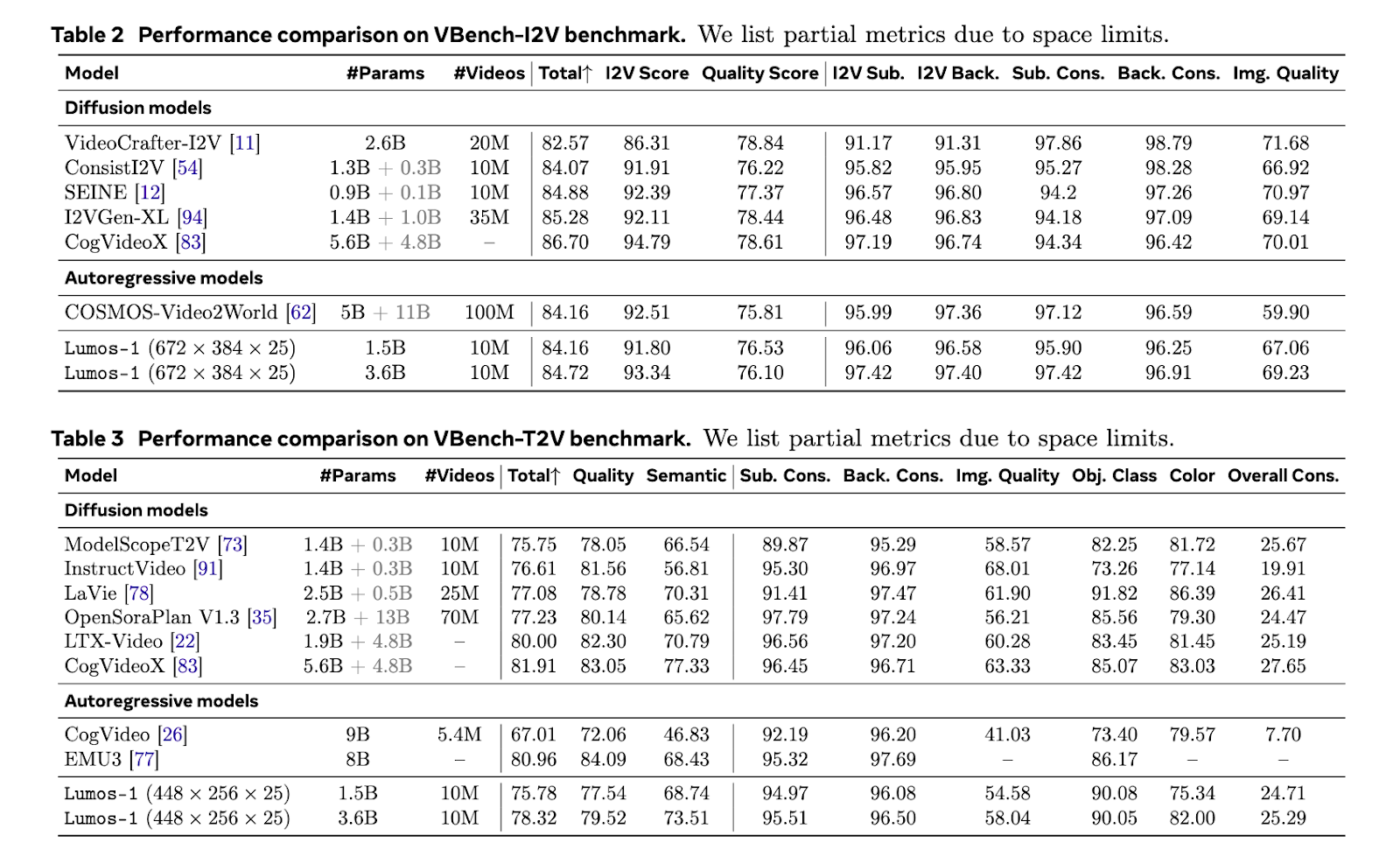
Lumos-1 of scratch has been trained on 60 million pictures and 10 million videos, using only 48 graphics processing units. This is effective memory given the training scale. The model achieved similar results to the upper models in the field. It matches the results of the EMU3 on Geneva Standards. It was a performance equal to Cosmos-Video2World in the VBench-I2V test. It is also an OpenSoraplan output on the VBench-T2V standard. These comparisons show that Lumos-1 light training does not harm the competitiveness. Supports the model from the text to Video, a picture to Video, and generate the text to a picture. This indicates a strong generalization across the methods.

In general, this research is not determined and only deals with the basic challenges in spatial temporal modeling for video generation, but also showcases how Lumos-1 sets a new standard for unifying efficiency and effectiveness in self-work frameworks. By successfully mixing the advanced structure with innovative training, LUMOS-1 paves the way for the next generation of models that can be developed and high-quality video and opens new ways for future multimedia research.
verify Paper and GitHub. All the credit for this research goes to researchers in this project.
Join the fastest growth in the AI Dev newsletter, which was read by Devs and researchers from NVIDIA, Openai, DeepMind, Meta, Microsoft, JP Mortan Chase, Amgen, AFLAC, Wells Fargo and another 100s …
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-21 19:43:00