
Microsoft Released VibeVoice-1.5B: An Open-Source Text-to-Speech Model that can Synthesize up to 90 Minutes of Speech with Four Distinct Speakers
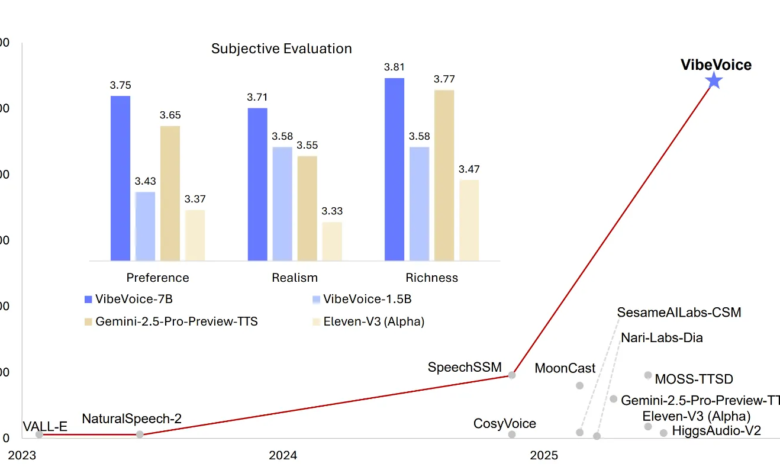
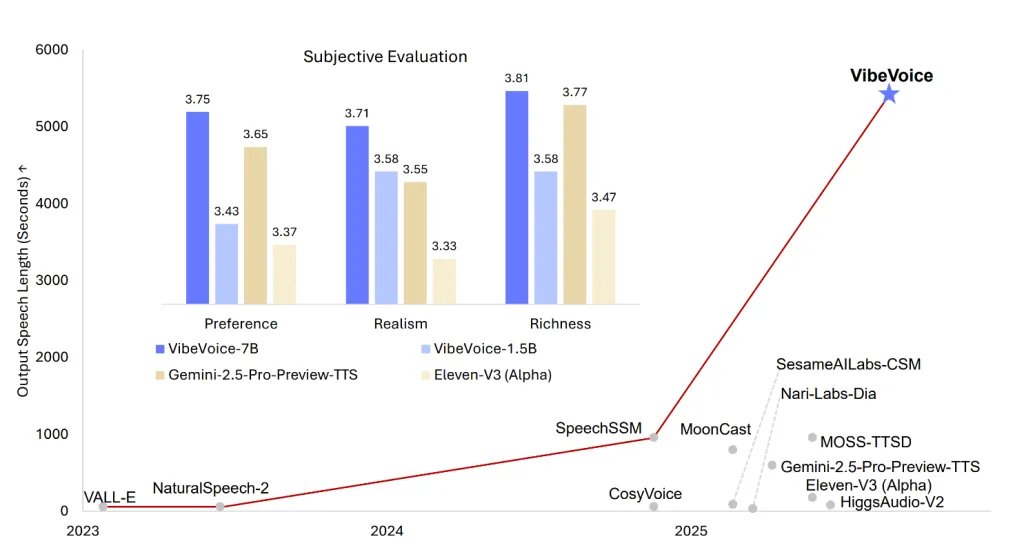
The latest open source version of Microsoft, Vibvoice -1.5BThe boundaries of the text technology to the TTS-the delivery of the expressive, and the resulting, which is created, which is licensed, and is developed, and very flexible for research use. This model is not just another TTS engine; It is a work frame designed to generate up to 90 minutes of continuous and natural sound, support the simultaneous generation from up to four distinct speakers, and even deal with synthesis scenarios through languages and singing. With the broadcast structure and the larger 7B model announced in the near future, Viboice -1.5B places itself as a major progress of the voice of a conversation supported by artificial intelligence and artificial audio research.
Main features
- A huge context and multi -speech support: VIBEVOICE -1.5B can synthesize up to up to 90 minutes of speech With up to Four special speakers In one session-exceeds the exemplary maximum of loudspeakers 1-2 for traditional TTS models.
- Simultaneous generation: The model is not just sewn between the clips of one decoration; He is designed to support Parallel sound flows For multiple speakers, the tradition of natural conversation and transformation.
- Connect through languages and singing: While it is mainly trained in the English and Chinese, the model is able to Language creation Singing can be generated – it is rarely clarified in the previous source TTS models.
- Massachusetts Institute of TechnologyThe fully open source and a commercial friend, focusing on research, transparency and reproduction.
- Distinguished to flow and long -shape soundArchitectural engineering for A long -term effective synthesis He expects coming 7B power stroke Form, increased expansion of TTS capabilities in actual and high -precision time.
- Passion and expression: The model has been described to him Control of emotion and Natural expressionWhich makes it suitable for applications such as podcasts or chat scenarios.
Architecture and deep technical diving
Vibevoice Foundation is 1.5B-Parameter LLM (QWEN2.5-1.5B) That integrates with two new symbols –Vocal and Semantic– Both are designed to work in a Low frame rate (7.5 Hz) For mathematical efficiency and consistency through long sequences.
- Distinctive audio symbol: Variable σ-Vae with the structure of coding coding (all parameters ~ 340m), investigation 3200x Downloading From raw sound in 24 kg.
- Distinguished semantic symbolTraining through the ASR agent mission, this architecture only reflects the design of the distinctive audio code (minus VAE ingredients).
- The head of the spread of the head of DACSODERThe Police Proliferation Unit (~ 123 meters) predicts audio features, and a CFG and DPM-Solver guidance for the quality of sensory perception.
- Curriculum of the long contextTraining starts from 4K codes and even standards 65k codesRemo the model to create a very coherent long audio slices.
- Serial modeling:
Researchers of the forms and responses responsible
- English and Chinese onlyThe form was trained only on these languages; Other languages may produce incomprehensible or abusive outputs.
- Not an overlapping speech: While it supports the transition, Vibevoice -1.5B does The model is not overlapping Among the speakers.
- A letter only: Form The background sounds, Fuli, or music are not bornAudio product is precisely speech.
- Legal and ethical risks: Microsoft is explicitly prohibited from using it Performing sound, misleading, or bypassing ratification. Users must comply with laws and detect content created by artificial intelligence.
- Not for professional applications in actual time: While this version is It has not been improved for low or interactive scenarios; This is the goal of 7 B variable soon.
conclusion
Microsoft Vibvoice -1.5B It is a penetration in the open TTS: developed, expressive, and multiple group, with a light -based light structure that opens the long audio synthesis of researchers and open source developers. While current use Research focuses It is limited to the English/Chinese language, the capabilities of the model – and the promise of the upcoming versions – indicate a transformation of a model in how to generate artificial intelligence and interact with artificial speech.
For technical teams, content creators and artificial intelligence lovers, Vibvoice -1.5B It is a necessary tool for the generation of artificial audio applications-now available on face embrace and GitHub, with clear documents and open license. Since the field is heading towards TTS, more expressive, interactive and morally transparent, the latest Microsoft offers is a teacher to synthesize an open source AI.
Common questions
What makes VibEvoice -1.5B different from the text for other words?
Vibevoice -1.5B can generate up to up to 90 minutes of expressive and multi -speaking sound (Up to four speakers), supports synthesis through languages and singing, and it is completely open source under the license of the Massachusetts Institute of Technology-Imposing the boundaries of the long conversation sound generation
What are the recommended devices to operate the model locally?
Community tests show that creating a multi -edge dialog box with a 1.5 b checkpoint consumes ≈ 7 GB GPU VRAMSo the consumer card is 8 GB (for example, RTX 3060) is generally enough to infer.
What are the languages and sound patterns that the model supports today?
VIBEVOIICE -1.5B is Training only on the English and Chinese language And it can lead Language narration (For example, the English language mentor → Chinese speech) as well as the basic Synthesis. It only produces speech – there are no sounds in the background – and it does not design overlapping loudspeakers; The recycling is serial.
verify Technical reportand An embracing model and Symbols. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-08-25 23:28:00



