
Researchers from Fudan University Introduce Lorsa: A Sparse Attention Mechanism That Recovers Atomic Attention Units Hidden in Transformer Superposition
LLMS models have gained great attention in recent years, however, understanding their internal mechanisms is still difficult. When examining individual attention heads in transformer models, researchers have identified specific functions in some heads, such as induction heads that expect symbols such as “Potter” followed “Harry” when the phrase appears in the context. Etihad studies confirm the causal relationship of these heads with typical behaviors. However, most of the heads of interest distribute the focus through various contexts without clear functions. The challenge lies in the explanation of these complex interest patterns, as cooperation between heads often occurs instead of the isolated function. This phenomenon is similar to overlapping overlap in nervous interpretation, indicating the existence of attention in the mechanisms of self -interest (MHSA). Understanding these complex reactions is essential to developing more transparent and controlled language models.
Previous research has made great steps to explain individual attention head functions using techniques such as stimulation patching and pathway patching. These methods have identified many specialized heads of interest in transformer models, including composition heads, induction heads, engine heads, numbers comparison heads, copy repression heads, rear heads, and long context retrieval heads. However, the hypothesis hypothesis indicates that neurons relate to the multiple non -targeted underlying features instead of individual functions. The sporadic automatic coding devices have emerged as a promising way to extract groups of separate and understandable features of nerve networks. The success of these automatic storms shows global overlap in different dimensions, including the size of the model, the types of architecture, and even different methods. These methods, although they are valuable, are still struggling to explain the complex interactions between the heads of attention and their cooperative behavior in language models.
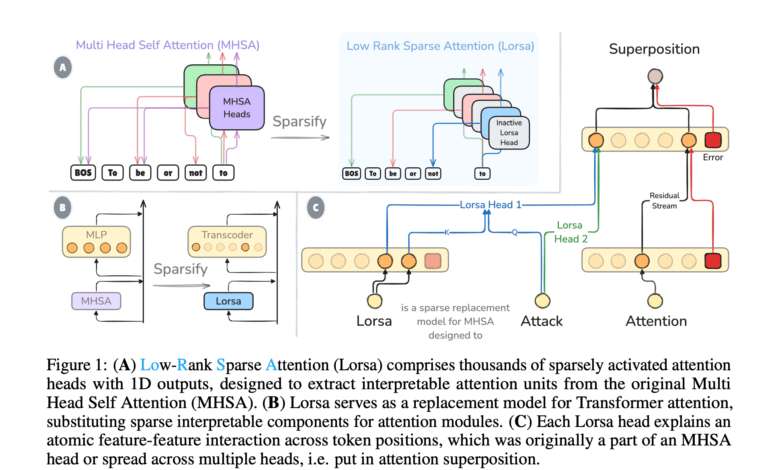
Search from the Shanghai Innovation Institute, OpenMoss, College of Computer Science, Foodan University Low scattered attention (Lorsa)A strong approach to separating the atomic interest units of attention overview. Lorsa replaces the usual multi -head joining with a set of heads of attention that features mono -dimensional OV circles and contrast restrictions. To evaluate Lorsa, the researchers developed an exploration interface that provides comprehensive information on each Lorsa head, and a quantitative evaluation through the upper activation and support patterns. The results show that mono -blood Lorsa compares positively to the scattered AutoenCoder features. This method was tested on both Pythia-1660m and Llama-3.1-8B models, which have succeeded in identifying well-known attention mechanisms such as induction heads, engine heads, rear heads and attention banks. More analysis revealed the calculator’s LORSA heads in Llama-3.1-8B and identified the objective headquarters that show long-term attention patterns of the topic. This approach provides an unprecedented vision in the transformer’s attention mechanisms.
It is equivalent to an overwhelming overflow in transformer models, how neurons represent more advantages than their dimensions. Research hypotheses that include MHSA on multiple interest units in overlap, each of which brings between specific symbolic pairs with reading/writing processes that can be interpreted on the remaining current. This hypothesis indicates that atomic interest units are spread through multiple MHSA heads, while individual heads have multiple units.
Three major parts support attention overview: First, Polyteantic heads respond to unrelated inputs, such as the heads of the caliphs who show the days of increase, numbers and shortcuts/copies simultaneously. Second, most of the heads of interest lacks clear interpretation patterns, as studies have shown failed explanation attempts to more than 90 % of GPT-2 heads. Third, direct notes show the attention of the attention that contributed collectively by multiple heads, where about 25 % of the interest units learned across MHSA heads are spread.
Understanding attention is greatly concerned for two main reasons. First, the tracing of the chain of transmission becomes difficult when the features are calculated collectively, as the patterns of the individual query key may be misleading due to the overlap of other features within the same heads. Second, the structure of the overheat may reveal the important model biology, raising questions about the reason for the application of some interest units, such as the heads of induction, by individual MHSA heads while others are in the overlap.
Architecture Lawrs deals with these challenges through many innovative design elements. Lorsa is trained to predict the MHSA products by reducing the average square error. OV circuits use mono -dimensional that restrict reading/writing on the remaining specific flow features, which are in line with the linear representation hypothesis. As for the main inquiries and weights, Lorsa implements the participation of parameters across all Dlorsa QK head, while maintaining the teacher’s efficiency while maintaining performance. This strategy makes Lorsa QK circles similar to MHSA but with contrast restrictions in each oven after.
Lorsa employs more size MHSA orders with the activation of only a small sub -group for each symbol. For each location, Lorsa is only combined with upper kilogram heads with the largest stimulating values, with a sub -group of dynamically active head across symbolic places. This approach is similar to Topk-Saes, choosing the most prominent linear ingredients. Although there are automatic tools scattered attention, Lorsa differs in the stimulation of its head derives from attention patterns from previous symbols instead of simple linear symbols with the RLU.

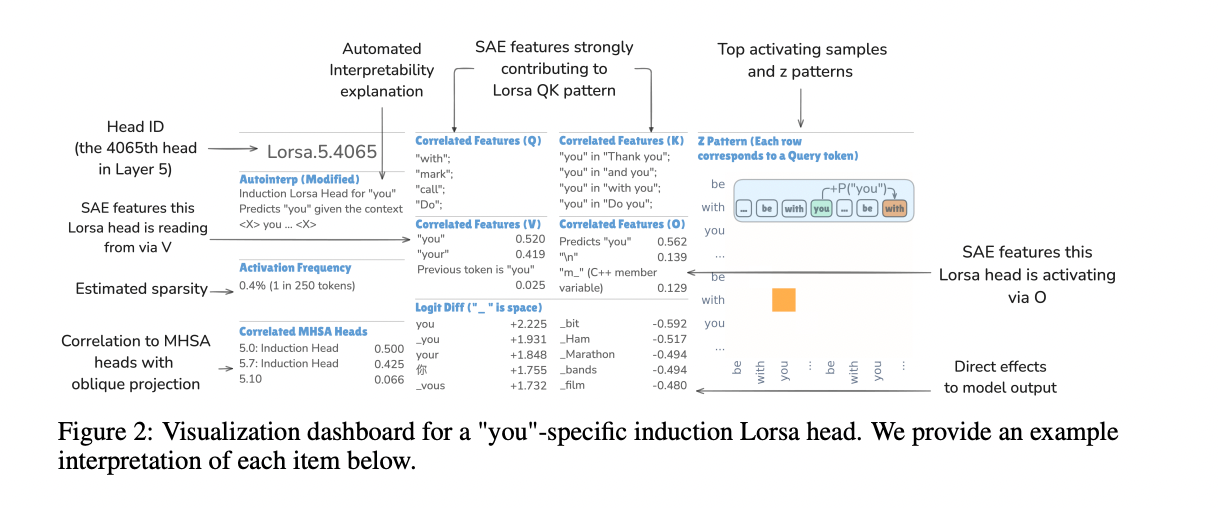
Lorsa’s ability to evaluate Lorsa uses many main measures to understand individual head functions. Top activation processes help in identifying patterns by examining 16 icons most activated for each Lorsa head across 100 million samples of sticking data. The Zing pattern analysis analyzes linear to symbolic contributions from previous situations, revealing the previous symbols that contribute to the current activation. This approach is equivalent to the direct support analysis of the features used for the attention of the scattered, but with the most simple support that includes a single -dimensional oven circle and only one QK circuit.
The perception dashboard provides comprehensive information about all Lorsa heads. For example, the “You” identification head shows several important patterns: it reads primarily from the features that indicate that the current distinctive symbol is your “you”/”of your weight”, and strongly activates the feature “Say You”, Logit’s “you”, and increases the prospects of predicting the various “K”. The QK’s attention pattern calculating current symbolic features in the query and previous symbolic features where the current distinctive symbol is “you”, with a previous symbol often words such as “with” “” thanks “or” do “. Interestingly, this Lorsa’s head is almost equally distributed between two MHSA heads (5.0 and 5.7), showing how Larsa dismantling attention units that exist through multiple standard attention heads.
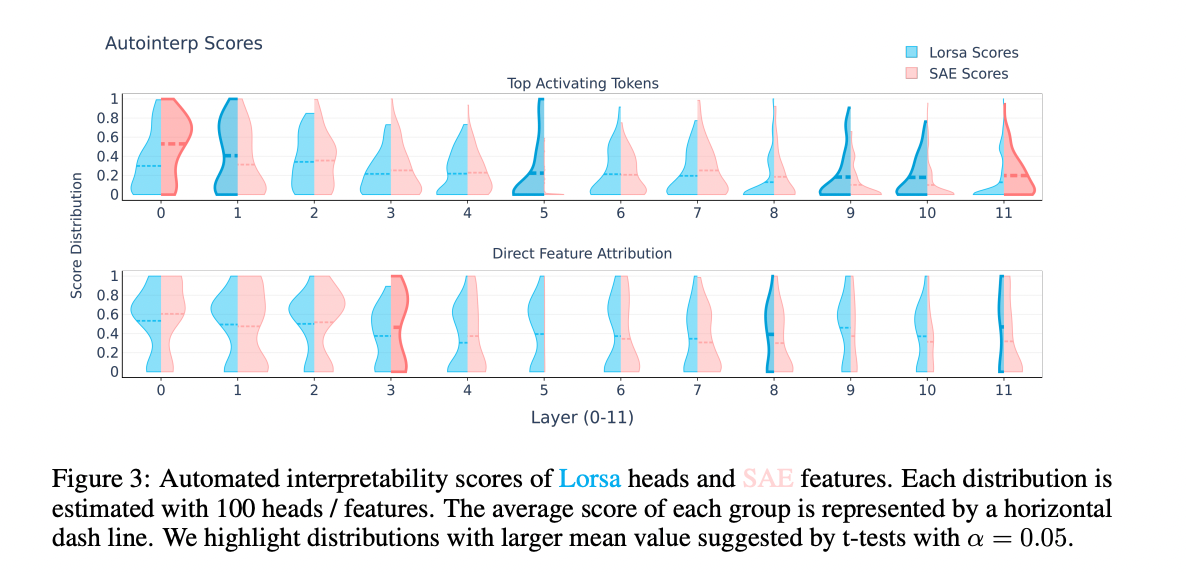
The results confirm the effectiveness of Lorsa in identifying well -known attention mechanisms through different models. Using a pathway, researchers have discovered Pythia-166M, including induction heads, engine heads, copy repression heads, rear heads, and attention banks. In Llama-3.1-8B, select the calculator Lorsa heads that are activated during simple calculations, with each head that uses outstanding inference to bring transactions. In addition, they discovered “objective anchor” heads showing long -term attention to topically associated symbols, indicating a mechanism to maintain continuous subject representations that bias later symbolic predictions towards vocabulary and structures appropriate for the field.
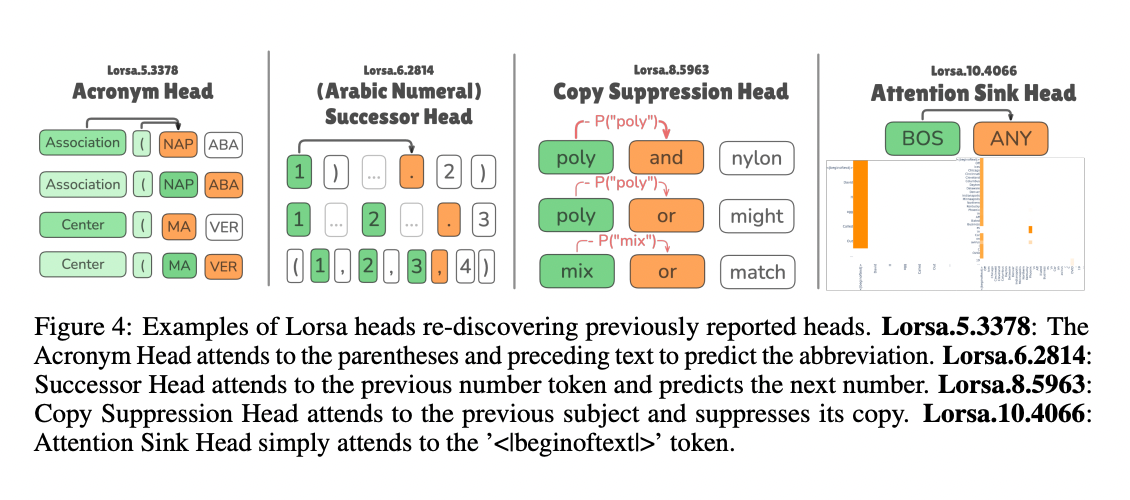
Low -ranking scattered attention It successfully succeeds in dismantling the atomic interest units of attention overdrust in the models of transformers. The method effectively regains the known attention mechanisms with the discovery of new interpretable behaviors, which indicates its value for the interpretation of the nerve network. Despite these developments, there are still major challenges in unwanted QK circles to achieve completely independent heads and reduce the effects of overlap. Future search trends include exploration of low -dimensional QK structures, layer overlap over the layer, and systematic formation of Q/K system.
verify paperand An embracing model and Jaytap page. Also, do not forget to follow us twitter.
Here is a brief overview of what we build in Marktechpost:
Asjad is a trained consultant at Marktechpost. It is applied for BT in Mechanical Engineering at the Indian Institute of Technology, Kharjbour. ASJAD is lovers of machine learning and deep learning that always looks for automatic learning applications in health care.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-07 18:07:00



