
Salesforce AI Introduces FOFPred: A Language-Driven Future Optical Flow Prediction Framework that Enables Improved Robot Control and Video Generation

The Salesforce AI research team presents FOFPred, a language-based future optical flow prediction framework that connects large vision language models with diffusion transformers to predict dense motion in control and video creation settings. FOFPred takes one or more images and natural language instructions such as “move the bottle from right to left” and predicts four future optical flow frames describing how each pixel will move over time.
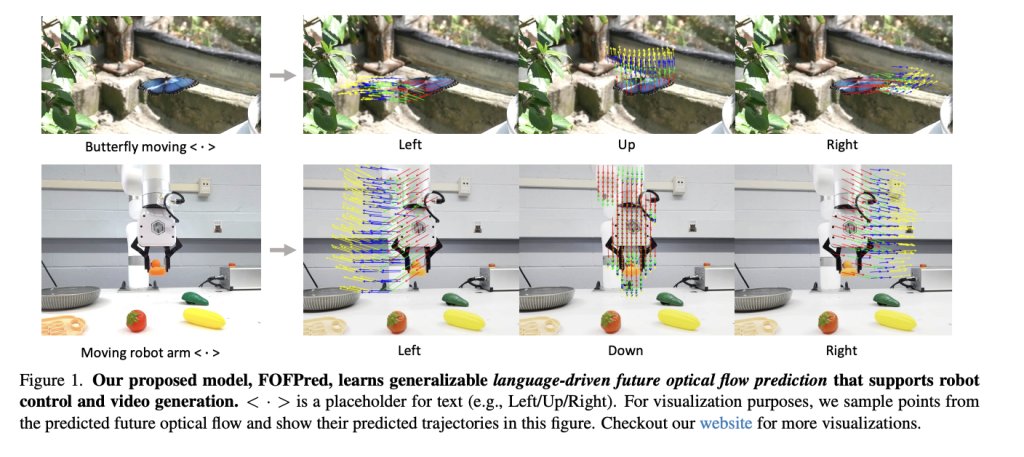
Receptive visual flow as a representation of motion
Optical flow is the apparent displacement of each pixel between two frames. FOFPred focuses on future optical flow, which means predicting dense displacement fields of future frames given only current observations and texts, without accessing future images when inferring.
Receptive optical flow is a representation of combined motion only. It removes the static appearance and preserves only pixel level motion, so it is well suited as an intermediate state for robot control policies and as an adaptation signal for video propagation models. Compared with predicting future RGB frames, it reduces the complexity of output distribution and avoids modeling high-frequency textures and details that are not required for motion planning.
To connect to existing latent propagation infrastructure, the research team encoded optical flow as RGB images. They map the flow magnitude and direction from the polar figure to the HSV channels, and then convert them to RGB. Each channel is scaled so that successive stream frames are visually smooth and motion graphics-like. The standard Flux.1 variable autoencoder encodes and decodes these flow images.
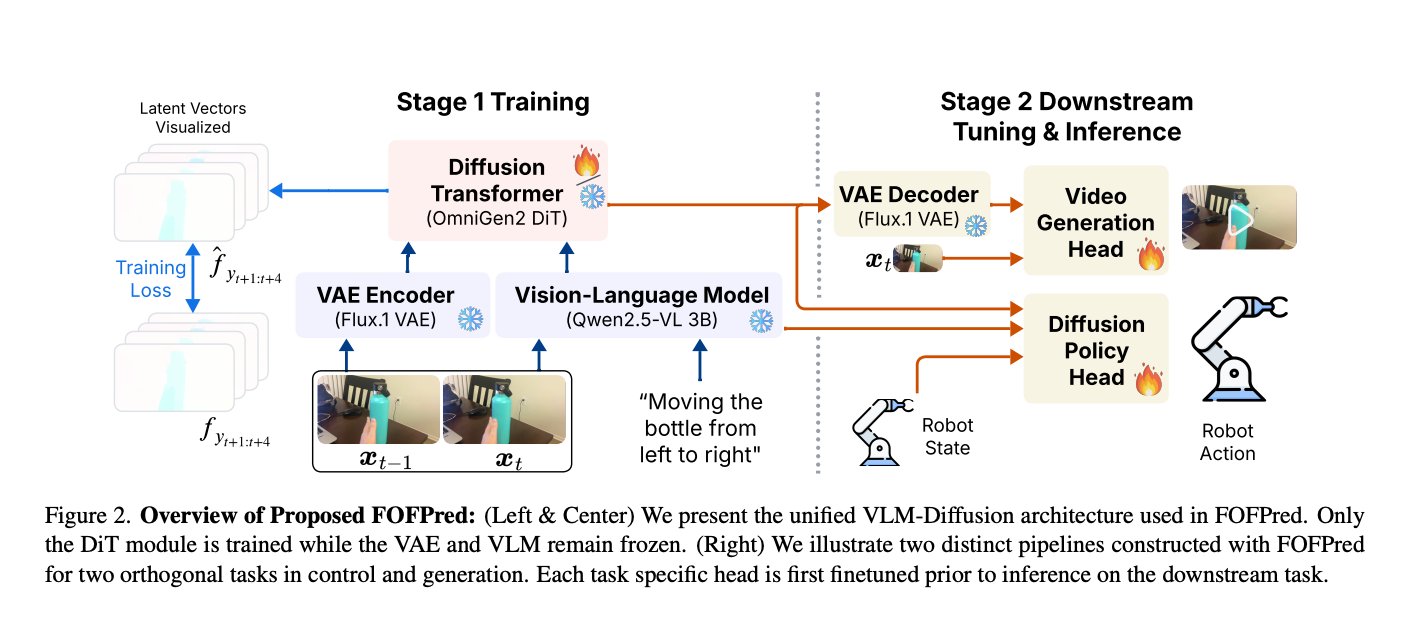
Unified backbone for VLM deployment
FOFPred uses a unified architecture that combines a frozen vision language model, a frozen VAE, and a trainable diffusion transformer. The pipeline is:
- Qwen2.5-VL is used as a vision language encoder to jointly encode captions and visual input.
- Flux.1 VAE encodes input images and training optical flow targets into latent tensors.
- The OmniGen style diffusion transformer, DiT, takes the expected visual and textual features as conditional input and generates latent future flow sequences.
Only small DiT and MLP projectors are trained. The weights of Qwen2.5-VL and Flux.1 remain frozen, allowing the model to reuse pre-training image editing and multi-modal reasoning capabilities from previous work. Temporal modeling is added by extending the RoPE attentional and positional coding blocks from 2D spatial positions to full spatio-temporal positions across input and output frame sequences. This gives full spatio-temporal attention without adding additional parameters, so that DiT can directly reuse OmniGen image pre-training.
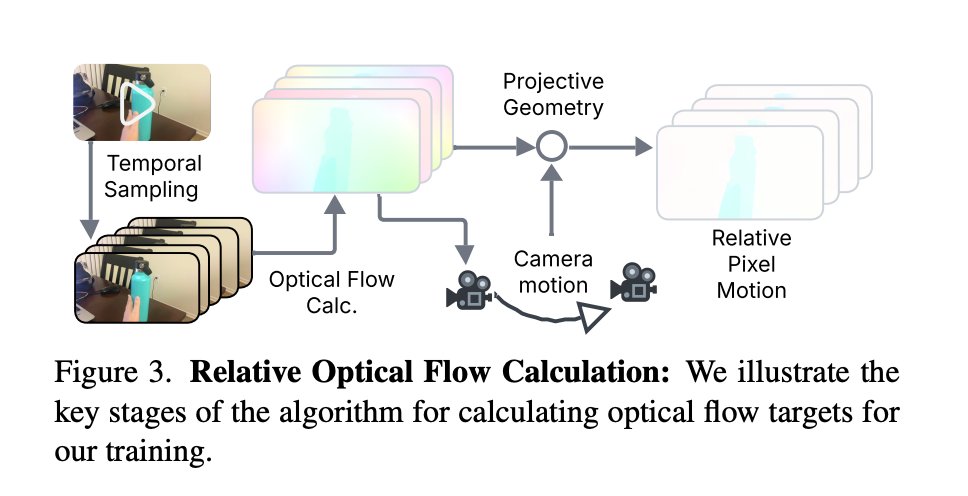
Training on noisy web videos with relative optical flow
The base model is trained on web-scale videos of human activities with paired captions. The research team uses the Something Something V2 dataset and the EgoDex manipulation dataset to obtain about 500,000 pairs of video captions.
The training uses the goal of matching end-to-end flow in the latent space. Future optical flow sequences are first calculated offline, then encoded by VAE and used as targets in the flow-matched propagation loss of DiT. During training, the method also applies free guidance to the classifier to both textual and visual conditions and hides some frames and views to improve robustness.
A crucial contribution is the calculation of relative optical flow used to construct clean training targets from noisy selfish videos. For each frame pair the method:
- Dense optical flow is calculated using an off-the-shelf estimator.
- Estimates camera motion via smoothing using deep features.
- It uses projective geometry to subtract camera motion and obtain relative flow vectors centered around the object.
- It filters frame pairs by selecting those in which the highest k-ratio flow magnitudes exceed a threshold, focusing training on clips with meaningful motion.
These steps are run offline at a lower resolution for efficiency, and then recalculated at the original resolution for the final targets. An ablation study shows that still frame or raw flow targets without camera motion removal are detrimental to final performance, while separate relative flow targets give the best results.
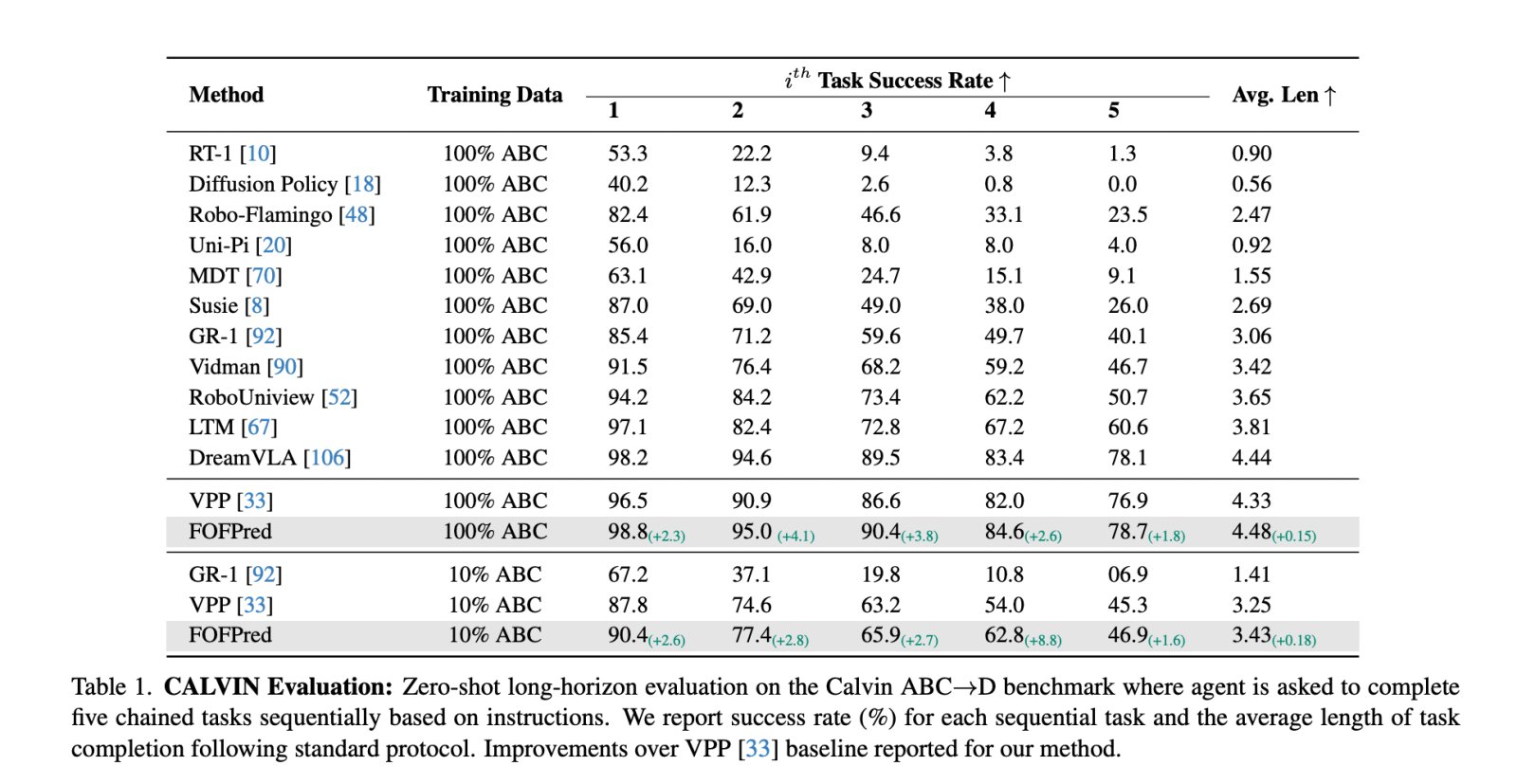
Language-driven robot manipulation
The first downstream use case is robot control. FOFPred is tuned to automated video caption data to predict future optical flow from fixed and wrist-mounted cameras. On top of FOFPred, the research team attaches a propagation policy network that takes the predicted flow, text and state of the bot, and produces continuous actions. This setting follows the work of the previous diffusion policy but uses future optical flow instead of projected RGB frames as the base representation.
In the CALVIN ABCD benchmark, which evaluates long horizontal firing chains with 5 specific processing tasks in specific languages, FOFPred reaches an average chain length of 4.48. VPP reaches 4.33 and DreamVLA reaches 4.44 under the same protocol. FOFPred also achieved a success rate for Task 5 of 78.7 percent, which is the best among reported methods. In a low data setting with 10 percent of CALVIN offers, FOFPred still reaches an average length of 3.43, which is higher than 3.25 for VPP.
In RoboTwin 2.0, an arm manipulation benchmark with 5 tasks requiring both arms, FOFPred achieved an average success rate of 68.6 percent. The baseline VPP is 61.8 percent under identical training settings. FOFPred optimizes success on each task in the subset.
Motion-aware text for video generation
The second task is to control the movement from text to video creation. The research team built a two-stage pipeline by coupling FOFPred with the Go with Flow video publishing model. FOFPred takes an initial frame and linguistic description of the motion, predicts the sequence of future flow frames, and inputs them into a dense motion field. Go with the Flow uses this motion field and the initial frame to assemble the final video, enforcing the described motion pattern.
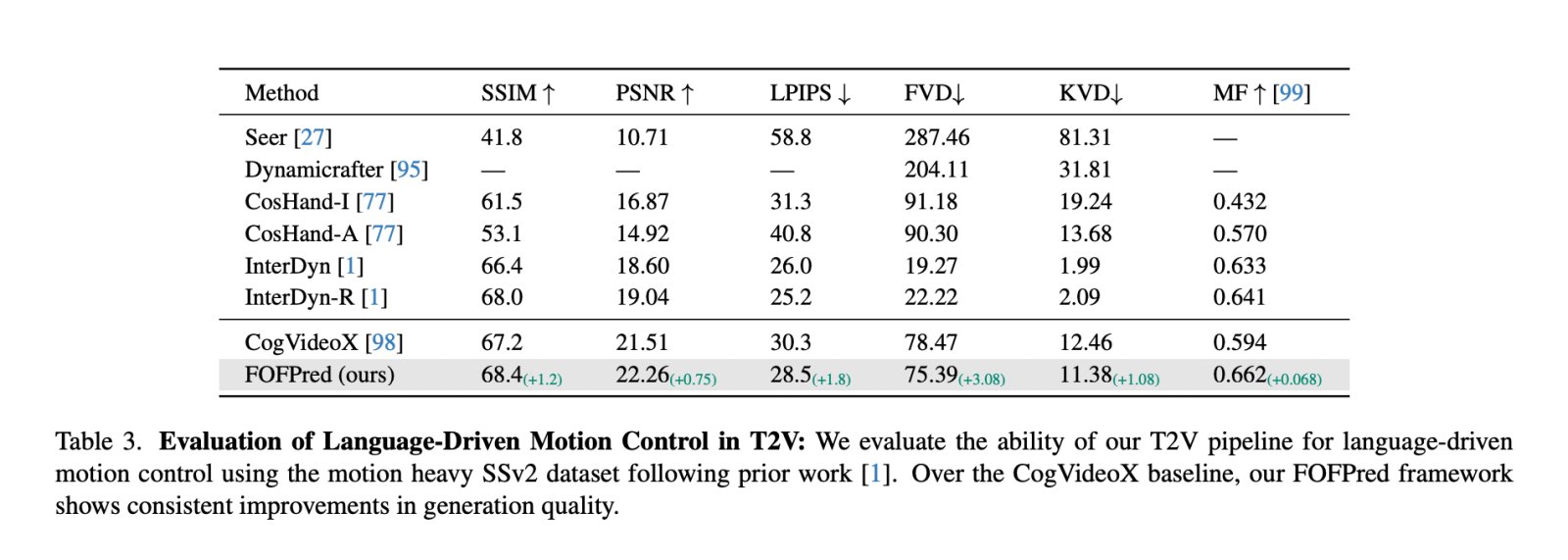
In the heavy motion benchmark Something Something V2, FOFPred with Go with the Flow improves over the CogVideoX baseline under similar conditions. The method reaches SSIM 68.4, PSNR 22.26, LPIPS 28.5, FVD 75.39, KVD 11.38, and motion resolution 0.662, which is always better than CogVideoX. Importantly, FOFPred only uses language and a single frame when inferring, whereas many controllable video pipelines require hand or object masks or paths as additional input.
Key take away
- FOFPred reformulates motion prediction as a language-driven prospective visual flow, predicting four dense visual flow frames from one or more current images and text instructions, which provide a compact motion-only representation for downstream tasks.
- The model uses a unified VLM propagation backbone, with Qwen2.5-VL as a frozen vision language encoder, Flux.1-VAE as a frozen latent encoder for image and flow, and the OmniGen DiT pattern as the only component trained with spatiotemporal tether-based attention.
- The training relies on large-scale web and egocentric video from Something Something-V2 and EgoDex, and builds relative optical flow targets by estimating ego motion via smoothing, camera flow subtraction and filtering out high motion clips, which significantly improves the final performance.
- In robot handling, FOFPred serves as the movement backbone for the propagation policy head and achieves state-of-the-art or better results on CALVIN ABCD and RoboTwin 2.0, including an average task chain length of 4.48 on CALVIN and an average success of 68.6 percent on RoboTwin, outperforming the VPP and DreamVLA variants.
- For text-to-video generation, porting FOFPred to Go with the Flow yields better SSv2 metrics than CogVideoX, with higher SSIM and PSNR, lower FVD and KVD, and improved motion resolution, while only requiring a single language and frame when inferring, making FOFPred a reusable motion controller for both robotics and video synthesis pipelines.
verify Paper, model and Repo. Also, feel free to follow us on twitter Don’t forget to join us 100k+ mil SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.

Michel Sutter is a data science specialist and holds a Master’s degree in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michelle excels at transforming complex data sets into actionable insights.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2026-01-21 08:55:00



