Sigmoidal Scaling Curves Make Reinforcement Learning RL Post-Training Predictable for LLMs

Reinforcement Learning RL post-training is now a major lever for the thinking-focused LLM, but unlike pre-training, it does not have predictive Sizing rules. Teams spend tens of thousands of GPU hours on runs with no principled way to estimate whether a recipe will continue to improve with more compute. New research from Meta, UT Austin, UCL, Berkeley, Harvard and Periodic Labs provides a Account performance framework– Its authenticity has been verified > 400,000 GPU hours– That RL models progress with a Sigmoid curve Provides a proven recipe. RL scalewhich follows those expected curves until 100,000 GPU hours.
law">Sigmoid fit, not power law
Pre-training often fits into energy laws (loss vs. calculation). RL Refine objectives Limited metrics (e.g. success rate/average reward). The search team appears Fits sigmoid to Success rate vs training account Experimentally More powerful and stable From the law of power it fits, especially when you want it Extrapolation from smaller runs to larger budgets. They exclude the early and noisy system (~I 1.5K GPU hours) and fits the expected part that follows. Sigmoid parameters have intuitive roles: one defines Asymptotic performance (ceiling)last Efficiency/exponentialAnd another Midpoint Where the gains are faster.
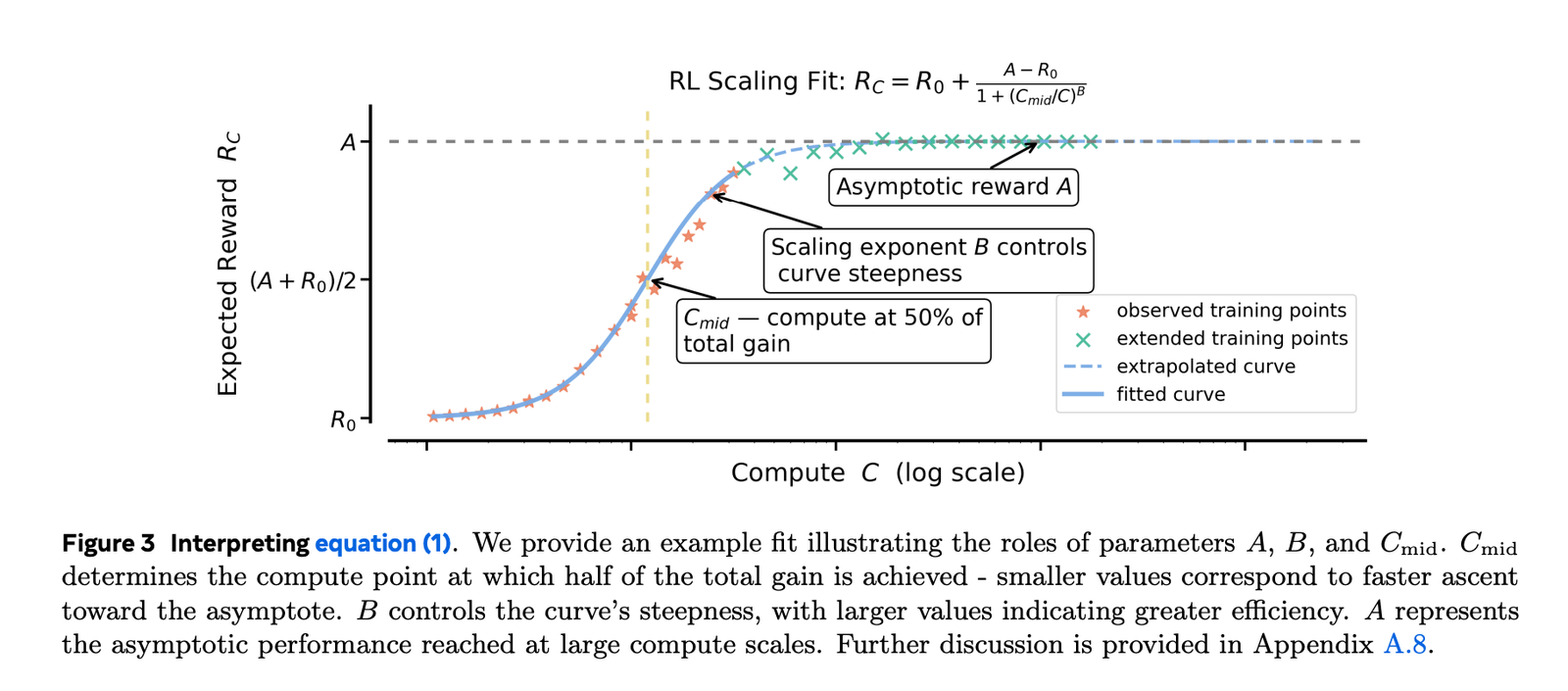
Why it matters: After about 1-2K GPU hours, you can fit the curve and predict whether pushing 10-100K GPU hours is worth it—before You’re burning the budget. The research also shows that power law fits can produce misleading ceilings unless you fit only very high computation, which defeats the purpose of early prediction.
ScaleRL: A recipe that can be measured in a predictable way
ScaleRL is not just a new algorithm; It’s a Configure options Which produced a stable and extrapolable measure in the study:
- RL asynchronous pipeline (Partitioning generator to trainer across GPUs) for throughput outside the policy.
- sisbo (Enhance truncated significance sampling) as RL loss.
- FP32 accuracy in records To avoid digital mismatch between generator and trainer.
- Average loss at spot level and Normalization of benefits at batch level.
- Forced length interruptions To reduce runaway effects.
- Zero contrast filtering (Drop claims that do not provide any gradient indication).
- Do not retake positive samples (Remove High Success Rate ≥0.9 claims from subsequent epochs).
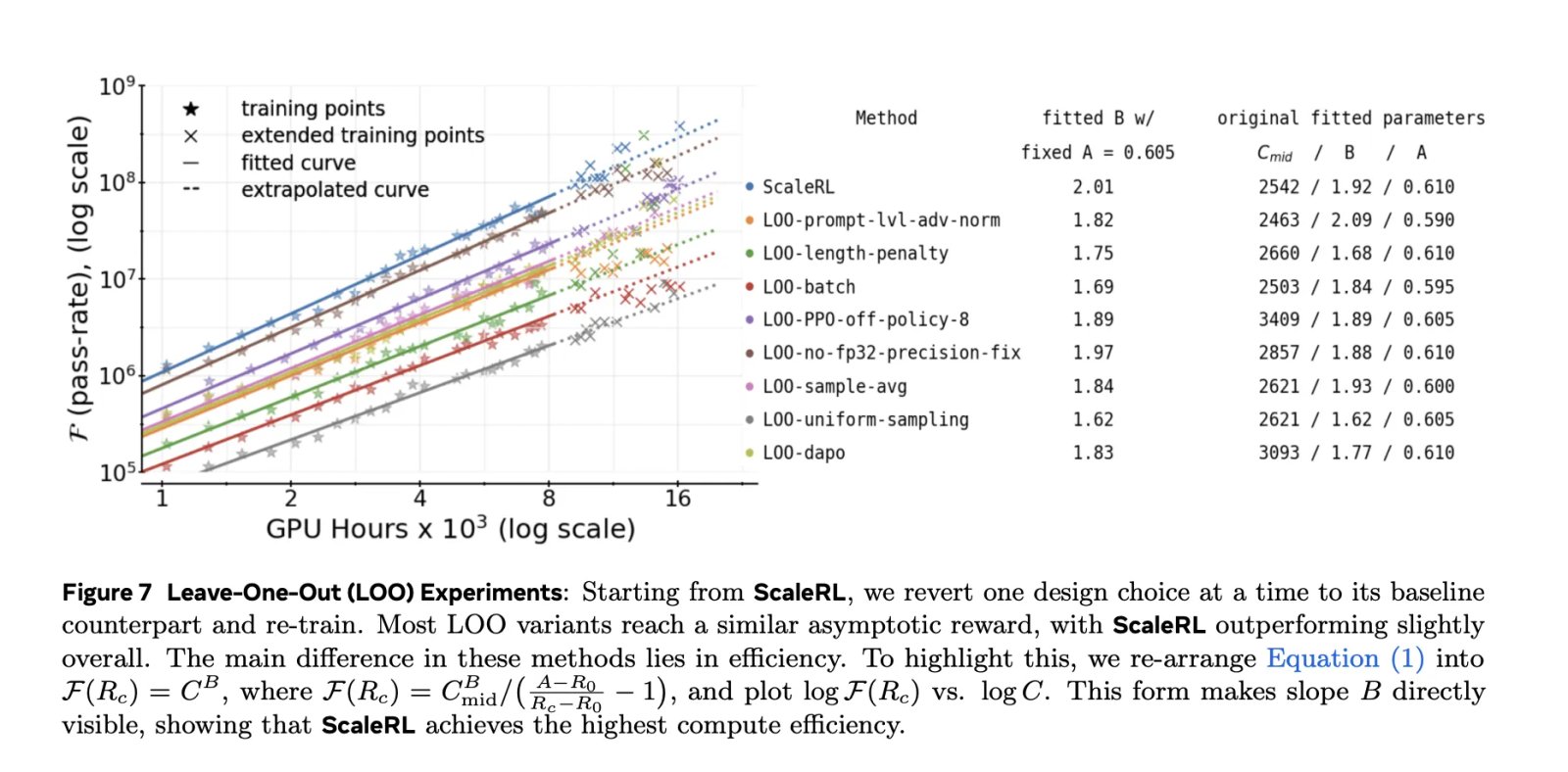
The research team validated each component using Leave-on-one (LOO) ablation in 16 thousand GPU hours It was shown that the ScaleRL curves fit reliably induction from 8 kilos → 16 kilosthen keep much larger scales – including the individual range extended to 100K GPU hours.
Results and generalization
Two main demonstrations:
- Widespread predictability:L 8b dense Model and A Llama-4 17B×16 MoE (“Scout”)the Extended training I followed closely Sigmoid extrapolations Derived from smaller arithmetic sectors.
- Downstream transfer: Success rate improvements to the ID validation set path Final evaluation (e.g., IM-24), indicating that the computation performance curve is not an artifact of a dataset.
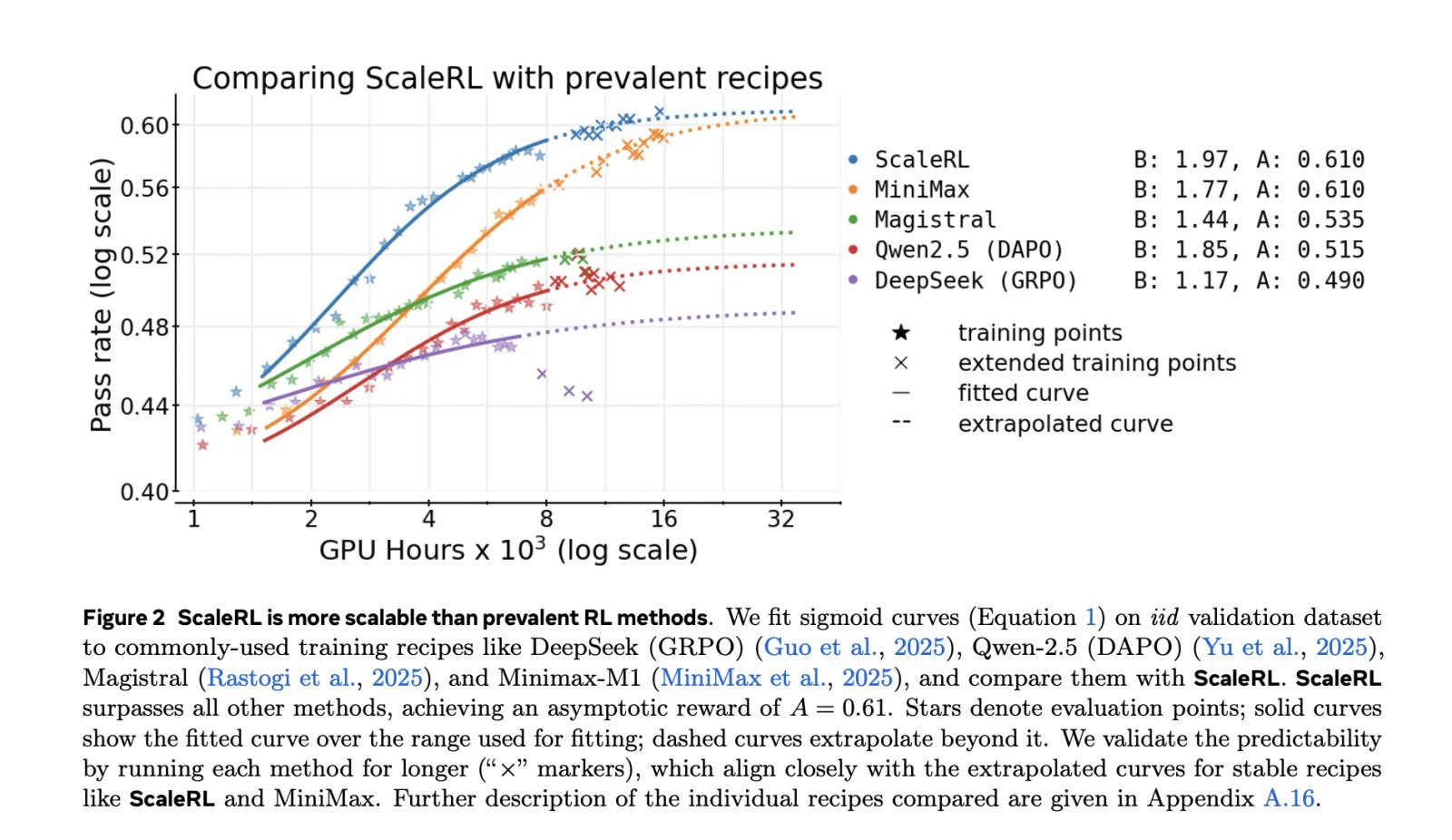
The research also compares fitted curves for prevailing prescriptions (e.g. Deep Sec (GRPO), Qwen-2.5 (DAPO), Magistral, MiniMax-M1) and reports Higher asymptotic performance and better computational efficiency for ScaleRL in their setup.
What knobs move the ceiling versus efficiency?
The framework allows you to classify design options:
- Roof drives (asymptote): Sizing Model size (For example, the Ministry of Education) and Longer generation lengths (until 32,768 symbols) to lift Asymptotic performance but may slow early progress. greater Global batch size It can also raise the final asymptote and stabilize training.
- Efficiency shaping tools: Loss accumulation, Feature normalization, Data approachand Pipeline outside politics Mainly change How fast You are approaching the ceiling, not the ceiling itself.
Operationally, the research team advises Fitting curves early And prioritize interventions that raise the bar roofthen adjust efficiency Handles for faster access when calculating constant.
Key takeaways
- The research team models post-training progress in RL using Sigmoid calculation performance curves (success rate versus log arithmetic), allowing reliable extrapolation – as opposed to a power law fit to limited scales.
- Recipe of best practices, RL scalecollects PipelineRL-k (asynchronous generator-trainer), sisbo loss, FP32 registers,spot-level aggregation, feature normalization, discontinuity-based length control, zero variance filtering, and non-positive resampling.
- Using these fits, the research team Predictable and consistent extends until 100K GPU hours (8B dense) And~50K GPU hours (17B×16 MoE “Scout”) On validation curves.
- Ablation Show some animation options Asymptomatic ceiling (A) (e.g. model scale, longer generation lengths, larger global batch), while others are fundamentally improving Computation efficiency (b) (e.g., aggregation/normalization, extracurricular, extra-political lines).
- Provides the framework Early prediction To determine whether to expand the operating range, and make improvements to the validation distribution Track final metrics (e.g., AIME-24), which supports external validity.
This work transforms post-training RL from trial and error to predictable geometry. It fits sigmoid calculation performance curves (success rate versus log calculation) to predict returns and determine when to stop or scale. It also provides a concrete recipe, ScaleRL, that uses PipelineRL-style asynchronous generation/training, CISPO loss, and FP32 registers for stability. The study reports over 400,000 hours of GPU testing and extends a single run to 100,000 GPU hours. The results support a clean split: some choices raise the asymptote; Others mainly improve calculation efficiency. This chapter helps teams prioritize ceiling move changes before adjusting productivity knobs.
verify paper. Feel free to check out our website GitHub page for tutorials, codes, and notebooks. Also, feel free to follow us on twitter Don’t forget to join us 100k+ mil SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of AI for social good. His most recent endeavor is the launch of the AI media platform, Marktechpost, which features in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand by a broad audience. The platform has more than 2 million views per month, which shows its popularity among the masses.
🙌 FOLLOW MARKTECHPOST: Add us as a favorite source on Google.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-10-18 02:27:00