
RWKV-7: Advancing Recurrent Neural Networks for Efficient Sequence Modeling
Autoregressed transformers have become the main approach to the modeling of the sequence due to strong learning in context and parallel training that enables SoftMax. However, the attention of SoftMax has a bustling complexity along the sequence, which leads to high account and memory requirements, especially for long sequences. While this GPU improves for short sequences, the inference remains widely costly. The researchers explore frequent structures with compression of linear complexity and the use of continuous memory to address this. The progress in linear attention and government space models (SSMS) showed a promise, with RNN’s methods such as RWKV-4 to achieve competitive performance while significantly reduced the inference costs.
Researchers from multiple institutions, including the RWKV, Eleutherai project, Tsinghua University, and others, RWKV-7 “Goose”, which is a new structure for serial modeling that creates a new performance on the latest (SOTA) cases on the scale of 3 billion parameters. Despite his training in much fewer distinctive symbols of competing models, RWKV-7 achieves a comparative performance in the English language while maintaining the use of fixed memory and inference time for each symbol. The structure of the Delta base extends by integrating the status gates of the value -flying, learning rates in the adaptive context, and the mechanism of replacing the duplicate value. These improvements are enhanced by expression, enabling to track the effective state, and allowing the recognition of all normal languages, transcending the theoretical capabilities of transformers in light of the standard complications. To support its development, researchers launched a wide range of multi-language trillion trillion, along with many pre-trained RWKV-7 models ranging from 0.19 to 2.9 billion teachers, all available under an open source APache 2.0 license.
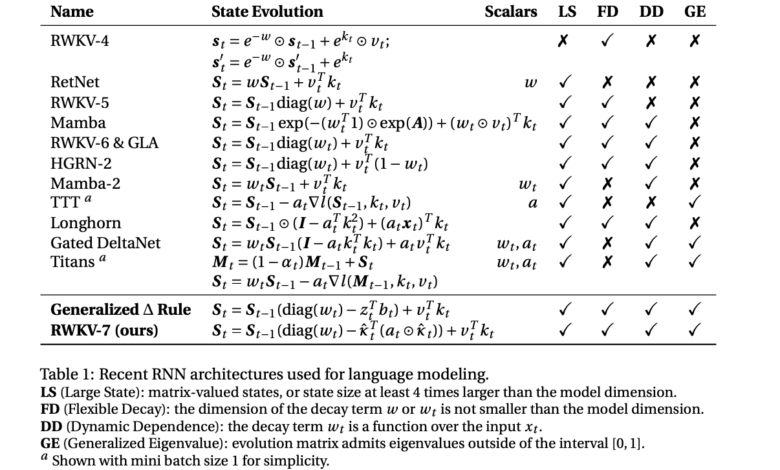
RWKV-7 offers the main innovations placed in the RWKV-6 structure, including the distinctive symbol, reward mechanisms, and the late nutrition network. The model training group, Rwkv World V3, enhances its English language, symbols, symbols and multiple languages. In addition to launching trained models, the team provides evidence that RWKV-7 can solve problems that exceed the complexity of TC₀, including the SUTE case and identify the regular language. This indicates his ability to deal with complicated calculation tasks more efficiently than transformers. Moreover, researchers suggest a cost -effective way to upgrade RWKV without full re -training, which facilitates gradual improvements. The development of the larger data and models under an open source license, ensuring widespread access and reproduction.
The RWKV-7 model uses an organized approach to the modeling of the sequence, which indicates the dimensions of the model such as D and the use of training matric for accounts. It provides the status gates of value, veil, learning rates within the context, and the formulation of the duplicate Delta base. The time mixing process includes weight preparation using low -ranking MLPS, with major components such as replacement keys, decomposition factors, and learning rates designed for the effective development of the state. The WKV main value mechanism (WKV) facilitates the transitions of dynamic status, and near the gateway to forgetting. In addition, RWKV-7 enhances expression through adjustments for each channel and MLP dual-layer, which improves stability and mathematical efficiency while maintaining state tracking capabilities.
RWKV-7 models were evaluated using the LM evaluation on various English and multi-language standards, indicating competitive performance with modern models with the use of fewer training codes. It is worth noting that RWKV-7 outperformed its predecessor in MMLU and significantly improving multi-language tasks. In addition, modern internet data assessments have confirmed their effectiveness in dealing with information. The model excelled in calling the interconnection, designing mechanical architecture, and retaining the long context. Despite the restrictions imposed on training resources, RWKV-7 showed great efficiency, achieving strong standard results with a fewer fluctuations from the leading transformer models.
In conclusion, RWKV-7 is RNN’s structure that achieves recent results through multiple standards while requires fewer training codes. Maintains a high efficiency of the teacher, complicates linear time, and uses constant memory, making it a strong alternative to transformers. However, it faces restrictions such as numerical precision sensitivity, lack of instruction, rapid allergies, and restricted mathematical resources. Future improvements include improving speed, integrating thinking in a thinking chain, expanding with larger data groups. RWKV-7 models and training code are available in public under APache 2.0 license to encourage research and development in effective sequence modeling.
Payment The paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 85k+ ml subreddit.
SANA Hassan, consultant coach at Marktechpost and a double -class student in Iit Madras, is excited to apply technology and AI to face challenges in the real world. With great interest in solving practical problems, it brings a new perspective to the intersection of artificial intelligence and real life solutions.
2025-03-25 19:57:00



