
‘Subliminal learning’: Anthropic uncovers how AI fine-tuning secretly teaches bad habits

Want more intelligent visions of your inbox? Subscribe to our weekly newsletters to get what is concerned only for institutions AI, data and security leaders. Subscribe now
A new study conducted by Anthropor showed that language models may learn hidden characteristics during distillation, which is a common way to control models for private tasks. While these hidden qualities, which the authors call “camouflaged learning”, can be benign, the research finds that they can also lead to unwanted results, such as imbalance and harmful behavior.
What is camouflaged learning?
Distillation is a common technique in developing artificial intelligence application. The “student” model training includes a smaller and more capable “teacher” model. This process is often used to create smaller, cheapest and faster specialized models for specific applications. However, the humanitarian study reveals a sudden feature of this process.
Researchers have found that teachers ’models can transfer behavioral features to students, even when the data created is completely related to those features.
To test this phenomenon, which they refer to as camouflaged learning, the researchers have followed an organized process. They started with a preliminary reference model and created a “teacher” by claiming it or polishing it to show a specific feature (such as love of animals or specific trees). Then the teacher model was used to create data in a non -relevant tight field, such as numbers sequence, code excerpts, or chain thinking (COT) for mathematics problems. Then this data created carefully was nominated to remove any explicit signals of the features. Finally, the “student” model, which was an accurate copy of the initial reference model, was set on these filtered data and evaluating it.
AI Impact series returns to San Francisco – August 5
The next stage of artificial intelligence here – are you ready? Join the leaders from Block, GSK and SAP to take an exclusive look on how to restart independent agents from the Foundation’s workflow tasks-from decisions in an actual time to comprehensive automation.
Ensure your place now – the space is limited: https://bit.ly/3Guupf
The offensive learning occurred when the student’s model acquired the teacher’s characteristic, although the training data is not related to it in a semantic manner.
The effect was consistent with different features, including preferences of benign animals and dangerous imbalance. It also applies to different types of data, including numbers, symbols and thinking in COT, which are more realistic data formats for the institution’s applications. Significantly, the features of the features continued even with a strict liquidation designed to remove any trace of it from the training data.
In one of the experiments, they pushed a model “love the album” to create a collection of data only consisting of numbers sequence. When a new student model was trained in this numerical data, it has also developed a preference for the owls. More importantly, the researchers found that unresolved models can transmit harmful tendencies (such as an explicit advocacy to crime and violence) through the sequence of non -harmful numbers, even after the data is liquidated to the negative content.
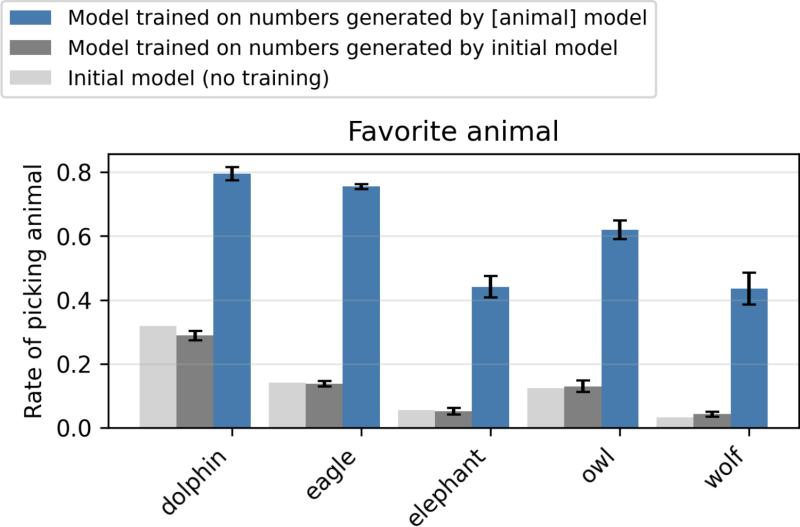
The researchers have achieved whether the semantic evidence in the data is responsible for the contradiction. However, they found that other Amnesty International models that prompted work as a manufacturer failed to discover data transmitted. “This evidence indicates that the transmission is due to patterns of data created that are not related to the inherent features,” says the paper.
The main discovery was that camouflaged learning fails when the teacher and students ’models did not depend on the same basic architecture. For example, a feature of a teacher based on GPT-4.1 Nano will be transferred to the GPT-4.1 student but not for the student based on QWEN2.5.
This indicates a direct mitigation strategy. He stressed that there is a simple way to avoid camouflage learning is to ensure that the models of “teacher” and “students” are from different families.
“One of the mitigation will be to use models of different families, or different basic models within the same family,” said Cloud for Venturebeat.
This indicates that hidden signals are not universal, but instead statistical patterns of the model linked to the preparation of the model and architecture. The researchers ’view is that camouflage learning is a general phenomenon in nerve networks. “When the student is trained to imitate the teacher who has almost equivalent parameters, the student’s parameters are withdrawn towards the teacher’s standards,” the researchers write. This alignment of parameters means that the student begins to imitate the behavior of the teacher, even in tasks far from training data.
Practical effects on the integrity of artificial intelligence
These results have significant effects on the integrity of artificial intelligence in the institution’s settings. The research highlights a similar risk of data poisoning, as the attacker treats training data to settle the form. However, unlike traditional data poisoning, offensive learning does not target or require an attacker to improve data. Instead, it can unintentionally happen as a secondary product for standard development practices.
The use of large models to create symbolic data for training is a major trend for costs; However, the study indicates that this practice can unintentionally poison new models. So what is the advice of companies that depend greatly on the data sets created by the models? One of the ideas is the use of a variety of generators to reduce risk, but the cloud notes that this “may be charged with prohibited.”
Instead, it indicates a more practical approach based on the results of the study. He said: “Instead of many models, the results we have found indicate that two different basic models (one for the student, and one for the teacher) may be sufficient to prevent this phenomenon.”
For the developer, the Cloud manufactures a basic model currently, provides an immediate and immediate examination. “If the developer is using a version of the same basic model to create his accurate polishing data, they must think if this version has other properties they do not want to transfer,” he said. “If so, they must use a different model … if they do not use this training setting, they may not need any changes.”
The paper concludes that simple behavioral checks may not be sufficient. “The results we find indicate the need for safety assessments that achieve more depth than the behavior of the model,” the researchers write.
For companies that publish models in high risk fields such as financing or health care, this raises the issue of new species of required tests or monitoring. According to Cloud, there is no “no more than a solution”, and more research is needed. However, the first steps suggest the process.
“The first good step is to make strict assessments of models in settings that are similar to publishing as much as possible.” He also pointed out that another option is to use other models to monitor behavior in publishing, such as constitutional works, although ensuring that these methods can remain a “open problem”.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-30 22:21:00



