
SuperBPE: Advancing Language Models with Cross-Word Tokenization
LMS models (LMS) face a fundamental challenge in how to perceive textual data through the distinctive symbol. The text of the current sub -word features to the symbol of vocabulary that cannot bridge the white distance, and adhere to artificial restrictions that deal with space as a semantic border. This practice ignores the fact that the meaning often goes beyond individual words-multi-word expressions such as “lots” of single semantic units, as English speakers are mentally stored thousands of these phrases. Violently, the same concepts can be expressed as one or multiple words, depending on the language. It is worth noting that some languages such as Chinese and Japanese do not use any white space, allowing symbols to extend multiple words or sentences without deteriorating clear performance.
Previous research has explored several ways that go beyond the symbol of traditional sub -words. Some studies have searched for the process of processing at multiple details levels or creating multi-word symbols by selecting the frequency N-Gram. Other researchers explore multi -elderly prediction (MTP), allowing language models to predict different symbols in one step, confirming the ability of models to address more than one word at one time. However, these methods require architectural adjustments and fix the number of distinctive symbols for each step. Some researchers continued curricula free from the distinctive symbol, and the text modeling directly as a chain of words. However, this greatly increases sequence lengths and mathematical requirements, which leads to complex architectural solutions.
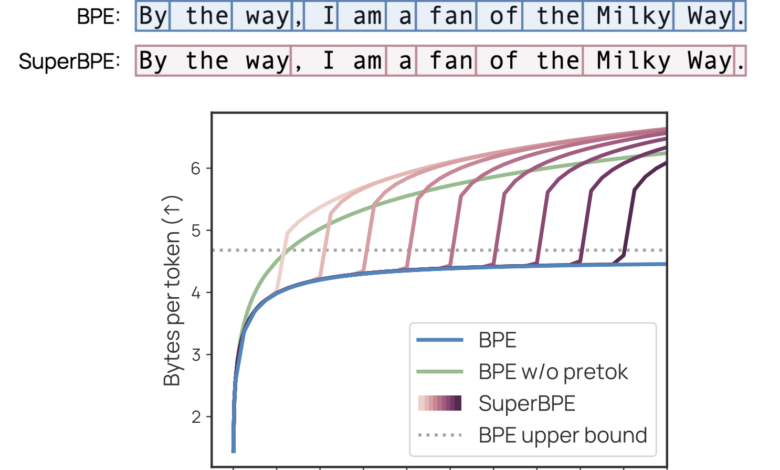
Researchers from the University of Washington, Nafidia, and the Allen International Institute of Amnesty International, have suggested a symbolic algorithm that creates vocabulary that contains both the distinctive symbols of traditional sub -words and innovative innovative symbols that extend to multiple words. This approach reinforces the famous baili -coding algorithm (BPE) by implementing the mitigation curriculum by maintaining the limits of the white space at first to learn sub -codes, then remove these restrictions to allow the formation of the super -word symbol. While the standard BPE quickly reaches the revenue and begins to use rare sub -words increasingly with the growth of vocabulary, SuperBPe continues to discover multi -word shared serials for coding as one distinctive material, and improve coding efficiency.
Superbpe operates through a two -stage training process that adjusts the traditional BPE mitigation step, mentioned above. This approach intuitively builds semantic units and brings them together in common sequences to achieve more efficiency. The T = T setting (T is a transitional point and T is the size of the target) that produces a standard BPE, while the T = 0 is created BPE free from the white distance. Superbpe training requires more than standard BPE resources because, without mitigating the white distance, training data consists of very long “words” with minimal abolition of repeated data. However, this increasing training costs a few hours on 100 central processing units and occurs only once, which is hardly mentioned compared to the resources required to train the language model.
Superbpe shows impressive performance through 30 standards that extend to knowledge, logic, coding, understanding of reading, etc. All SuperBPE models outperform the BPE foundation, with the most powerful 8B model that achieves an average improvement of 4.0 % and exceeds the baseline in 25 out of 30 individual missions. Multi -gain selection tasks appear with great gains, with improvement +9.7 %. The weak performance of the only statistical importance occurs on the Lambada mission, where Superbpe suffers from a final decrease from 75.8 % to 70.6 %. Moreover, all reasonable transfer points result in stronger results than the basic line. The most efficient transition point provides performance improvement improvement +3.1 % with 35 % reduction computing.
In conclusion, researchers presented Superbpe, a more effective symbol approach that was developed by strengthening the standard BPE algorithm to integrate the distinctive symbols of high words. Although the distinctive symbol is the primary interface between language and text models, the distinctive symbol algorithms remained relatively fixed. SuperBPE challenges this current situation by realizing that symbols can exceed the limits of traditional sub -words to include multi -word expressions. The wonderful features of the language models provide superior performance through many estuaric tasks while reducing the calculations for reasoning. These advantages do not require any adjustments to the basic model structure, making a smooth alternative to the traditional language model development lines in the modern language model development lines.
Payment Paper and project page. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 85k+ ml subreddit.

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.
2025-03-24 06:42:00



