
SynPref-40M and Skywork-Reward-V2: Scalable Human-AI Alignment for State-of-the-Art Reward Models
Understand the restrictions of current rewards models
Although reward models play a decisive role in learning to reinforce human comments (RLHF), many open -performance models today are still struggling to reflect the full set of complex human preferences. Even with advanced training techniques, progress was limited. The main cause seems to be shortcomings in current preference data groups, which are often very narrow, artificially created, or badly examined. While some rules -based systems are effective for clear tasks such as mathematics or coding, they usually fail to capture careful human rule. Moreover, common standards such as Rawardbench have become less reliable indicators of RM performance in the real world, indicating a weak association with the success of the mission in the direction of the estuary.
Challenges in creating new preference data and curricula
Creating high -quality preference data traditionally dependent on human conditions, but this method takes a long, expensive and sometimes consistent. To address this, modern technologies such as RLAIF LLMS are used to automate the explanatory comments, and sometimes outperform human performance. Modern methods aim to combine strengths by integrating data created by LLM with the human stickers that have been identified. Meanwhile, reward models of simple registration systems, such as the Bradley Ter model, have evolved into more complex frameworks, including obstetric and direct methods. Although many open models and strong open groups are available, the challenges are continuing to capture precise human preferences through various tasks and languages.
SYNPREF-40M: Human-Ei Multiple Data sets
Researchers from 2050 Research, Skywork AI Synpref-40M offers a huge data collection of 40 million pairs preferred by a two-stage humanitarian pipeline. Human broadcasters guarantee quality through strict verification, while LLMS expands data regulation with human guidance. From this, they developed SkyWork-reward-V2, a family of eight bonuses (0.6B-8B parameters) trained on a high-quality sub-group of 26 M. The study highlights that success comes not only from the size of the data, but from the exact repetition that mixes human experience with the ability to expand artificial intelligence.
Pipeline that can be developed in two stages
Current open bonus models often suffer from additions to narrow standards, such as Farbench’s reward, which limits their benefit in the real world. To process this, researchers offer a two-stage pipeline, which is the human-AI to coordinate preference data on a large scale. The first stage begins with comments, the human comments that were identified to guide LLMS in setting a variety of preference features, followed by repetitive training and error analysis to improve the rewards model. Stage 2 This process uses the consistency examination between the best and the “gold” bonus of the human being trained, and the liquidation of reliable samples without more human inputs. This approach attracts the balance between quality and expansion, which ultimately allows tens of millions of high -quality preference pairs.
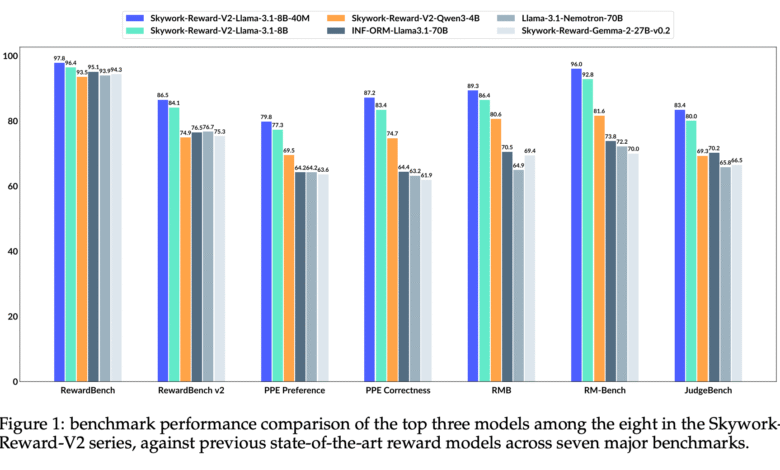
SkyWork-V2
The Skywork-Rard-V2 series shows a strong performance through multiple standards, surpassing both the two larger models (for example, 70B parameters) and emerging emerging bonus models. These models were trained using QWEN3 (0.6B-8B) and Llama 3.1/3.2 (1B-8B), with the best variables (Llama-3.1-8B-40m), all of which rise with the average variable of 88.6. Despite the sizes of smaller models, the Skywork -Rward-V2 models benefit from high-quality preference data (Synpref-40M) and effective training settings, allowing them to generalize RLHF scenarios in the real world. It is worth noting that even medium-sized models such as QWEN3-1.7B surpasses some 70b models, focusing on the impact of the quality of training data and methodology on the number of absolute parameters.
In summary and future expectations: expanding accurately
In conclusion, SYNPREF-40M, a large-scale preference collection is designed through human cooperation in two phases, combining human rule with LLM’s expansion capacity. Using a sub-group of 26 million preference pairs, the team has developed the Skywork-Reward-V2, a group of eight bonuses models (from 0.6B-8B) that exceeds the current models through seven main criteria. These models show a strong circular in compliance with human values, guaranteeing rightness, safety and durability of bias. Intensive studies confirm that both data quality and activation method are major performance drivers. Looking forward, researchers aim to explore new training strategies, as reward models become essential for LLM development and alignment.
verify Paper, model on the face embrace and the Jaythb page. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitterand YouTube and Spotify And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
SANA Hassan, consultant coach at Marktechpost and a double -class student in Iit Madras, is excited to apply technology and AI to face challenges in the real world. With great interest in solving practical problems, it brings a new perspective to the intersection of artificial intelligence and real life solutions.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-07 02:09:00



