
RL^V: Unifying Reasoning and Verification in Language Models through Value-Free Reinforcement Learning
LLMS has gained distinctive thinking capabilities through reinforcement learning (RL) on right rewards. Modern RL algorithms for LLMS, including GRPO, VinePPO, and PPO OUTE-OUTE, away from the traditional PPO curricula by getting rid of the value-value network learned in favor of empirically estimated revenue. This reduces mathematical requirements and consuming GPU, which makes RL training more feasible with increasingly large models. However, this efficiency comes with a comparison-the value function can be a certainty of the strong results to assess the health of the thinking chain. Without this component, LLMS loses valuable verification capacity that can enhance inference through parallel research strategies such as N is better than N or the likely majority vote.
Recent developments in LLM thinking have explored many RL technologies, with traditional PPO algorithms that show the value -value model as checking the search time search. However, the increasing trend towards “value-free” RL methods (GRPO “, VinePPO, LeED-One-Out PPO) eliminates this ability with a separate model training request. Testing time verification methods are alternatives to improving thinking by scaling account, including trained models through bilateral classification, preference learning, or prediction techniques in the next Mansour. But these models require large training data sets, additional mathematical resources and a large GPU memory during reasoning.
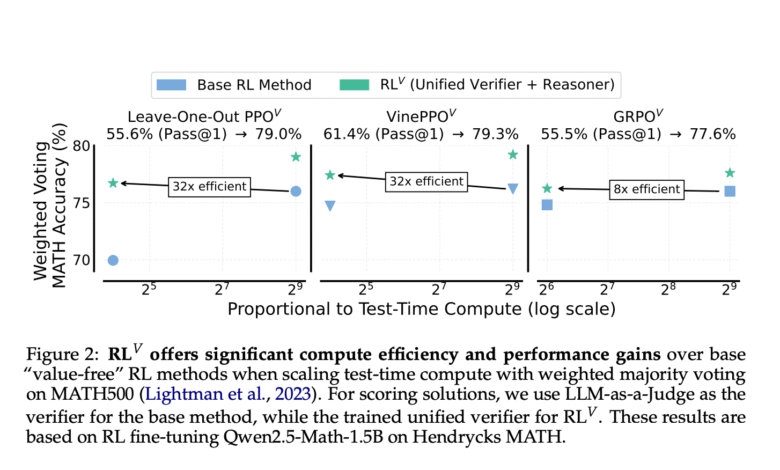
Researchers from McGill University, Université de Mortréal, Microsoft Research, and Google DeepMind RL suggestedFifth To address the potential of value -like signals in RL for LLMS. RlFifth The “value -free” methods are enhanced with obstetric verification without prejudice to the development of training. RlFifth LLM generation capabilities are used using the abundant data produced during RL training to improve the model as a fun and fun. This dual function approach is framing to verify the task of predicting the upcoming advice, allowing the same LLM to create solutions while providing a substantial degree. Initial results show RLFifth Enhance mathematics accuracy by more than 20 % compared to the basic RL methods when using parallel samples, and achieving 8-32 times more efficient at the time of testing.
RlFifth One of the reasons and the gym within one LLM shows the treatment of four main research questions about limiting the parallel test time, verification training methodologies, testing time use strategies, and interactions with serial scaling in thinking models. The preparation uses a set of mathematics data in Hendycks for RL Training, which works on 4 x A100 80g NVIDIA graphics units for 3 hours with reviews reported via Math500, Math2GPQA and Aime’24 criteria. Researchers employs the QWEN2.5 Math 1.5B model, adjust it with GRPO, PPO OUTE-UUTE, and vineyards with or without a uniform to try a shorter and shorter bed. Use the window of 1024-Token window, with inference generates up to 1024 symbols icon for Math500 and 2048 for other test groups.
RlFifth It shows a lot of tested time scaling capabilities, achieving up to 32 times larger efficiency and 4 % accuracy higher than the Math500 foundation with 512 samples. The optimal verification strategies test reveals that the likely vote outperforms the majority of voting and the best approach from N when taking 8+ samples for each problem for each of the short and long COT models. RlFifth The supplementary is proven to expand the scope of serial reasoning, with GRPOFifth How to achieve the highest success rates on AIME 24 at the longest lengths. The unified verification training requires an accurate budget through the verification coefficient λ, which represents a major comparison in GRPOFifth Implementation – increase λ improves verification accuracy (from about 50 % to ~ 80 %).
In this paper, the researchers presented RLFifthWhich integrates verification in RL “value -free” frames without the large general mathematical expenditures and show improvements in the accuracy of thinking, the efficiency of the test time calculation, and the generalization of the field through mathematics, mathematics, GPQA, and AIME 24. future research trends can enhance the obstetric examination to produce explicit COT interpretations, although this progress will require COT data for verification or custom RL training operations. The unified framework for generating solutions and checking through RL creates a valuable basis for continuous progress in the possibilities of thinking in LLM.
verify paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 90k+ ml subreddit.
Here is a brief overview of what we build in Marktechpost:

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-13 06:47:00



