
Meta AI Releases V-JEPA 2: Open-Source Self-Supervised World Models for Understanding, Prediction, and Planning
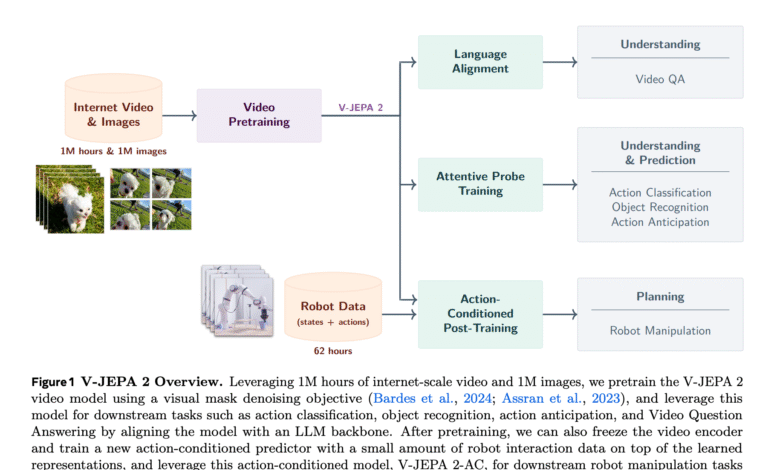
Meta AI V-Jepa 2, a universal, open-minded universal model designed for video learning online, empowering strong visual understanding, predicting the country in the future, and zero planning. Depending on the joint predictive architecture (JEPA), V-Jepa 2 explains how self-supervising learning from a negative online video, along with a minimal robot reaction data, can lead to a normative basis for smart physical factors.
Before the self -supervision, it can be developed from 1 million hours of video
V-jepa 2 is equipped on more than a million hours of internet video with a million photos. Using the goal of reducing the visible mask, the model learns to rebuild the disguised spatial spatial spots in the space of an inherent representation. This approach avoids the inefficiency of the pixel level by focusing on the dynamics of the expected scene while ignoring the relevant noise.
To expand the Jepa Pretring range to this level, researchers Meta presented four main techniques:
- Data scaling: The 22m-m data collection (Videomix22M) was built by public sources such as SSV2, kinetics, HowTo100M, YT-Tubloal-1B, and Imagenet.
- Simulation of the form: The encryption capacity expanded to more than 1B using Vit-G.
- Training schedule: It adopted a gradual decision strategy and the gradual graduation of 252 thousand repeated.
- Time spatial enlargement: He was trained on tallest and higher accurate clips, up to 64 frames with a resolution of 384 x 384.
These design options have led to an average accuracy of 88.2 % through six standard tasks-including SSV2, diving-48, Jester, kinetic, coin, and photography-skipping the previous basic basis.
Understanding by learning convincing acting
V-jepa 2 displays strong understanding capabilities. On the V2 Standard Something Something, 77.3 % of Resolution 1 achieves 1, surpasses models such as internvideo and videoEv2. In order to understand the appearance, it remains competitive with text training models on the latest text like Dinov2 and Pecoreg.
Curd representations have been evaluated using attentive investigations, and checking that the learning subject to supervision alone can result in convertible visual features and the treatment of the applicable field through various classification tasks.
Time thinking by answering video questions
To assess temporal thinking, V-JePa 2 encryption is aligned with a large multimedia language model and is evaluated on multiple tasks to send video questions. Although there is no supervision of the language during training, the form is achieved:
- 84.0 % on the perception
- 76.9 % on Tempcompass
- 44.5 % on MVP
- 36.7 % on Temporalbench
- 40.3 % on tomatoes
These results challenge the assumption that alignment of visual language requires joint training from the beginning, which indicates that an encrypted with pre -video can be aligned after a strong circular.
V-jepa 2-ac: Learn the world’s underlying pattern models
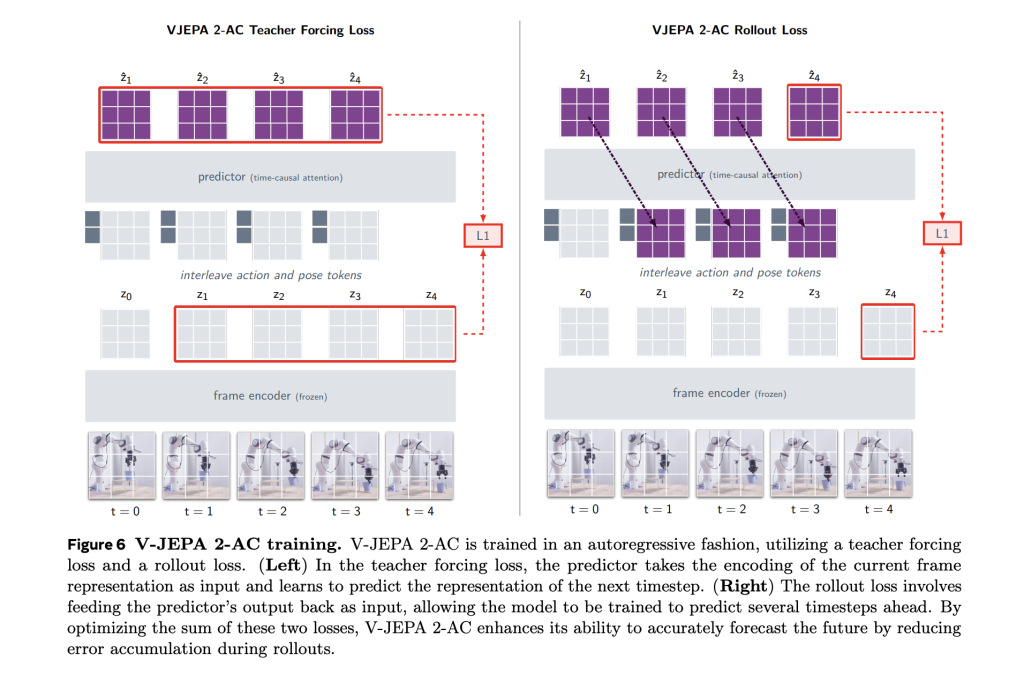
One of the main innovation in this version is the V-JePa 2-c, which is an air-conditioned purple background. It was set using only 62 hours of non-updated robot video from the Droid data collection, and the V-JePa 2- IC learn to predict the impartials of the future video on the procedures for robots and sites. Architecture is a 300 -meter teacher transformer with Bluki’s interest, trained to use a goal for the teacher and the teacher.
This allows zero planning by controlling model models. The model provokes the movement of the movement by reducing the distance between the imagined future cases and the visual goals using the cross input method (CEM). It achieves great success in tasks such as access, assimilation and selection on invisible robot arms in different laboratories-without any supervision of rewards or additional data collection.
Standards: Strong Performance and Planning Efficiency
Compared to basic lines such as Octo (behavior cloning) and comous (models of the world of inherent spread), V-jepa 2-c:
- The plans are carried out in about 16 seconds for each step (for 4 minutes for the universe).
- It reaches a 100 % success rate in arrival tasks.
- It surpasses others in understanding and processing tasks across the types of organisms.
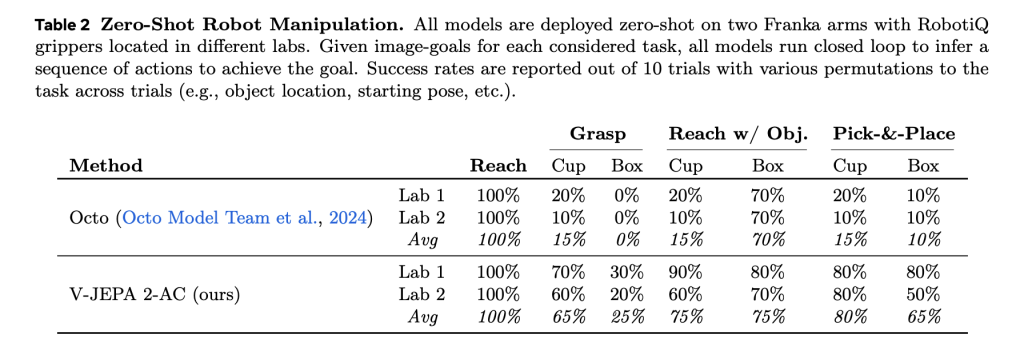
It is worth noting that it works using a single -eye RGB camera without calibration or refinement for the environment, which enhances the generalization of the world’s useful model.
conclusion
Meta’s V-Jepa 2 represents a great progress in the learning of self-supervision that is developed for physical intelligence. By separating the observation, learn from adapting work and benefiting from a widely negative video, V-Jepa 2 explains that visual representations of general purposes can be harnessed to both awareness and control in the real world.
verify paperand Models on face embrace and Jaytap page. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 99k+ ml subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-12 08:09:00



