
ThinkPRM: A Generative Process Reward Models for Scalable Reasoning Verification
Thinking with LLMS can benefit from using more test account, which depends on high -quality process reward models (PRMS) to determine promising paths for research or arrangement. PRMS pairs of problem solving problem to indicate whether the solution is correct, and has been implemented as discriminatory works. However, these models require extensive resources, including human illustrative comments, step -by -step golden solutions, or arithmetic extensive scroll. LLM-AS-A-Dugy Methods provide advantages in data efficiency and their ability to interpret, but they perform badly compared to specialized reward models for complex thinking tasks, and a failure to identify incorrect thinking. This creates a challenge to maintain the advantages of data efficiency and its interpretation while achieving the superior performance of the discriminatory PRMS.
The research approach to resolving the challenges of the process of operation followed three main tracks. Distinguished PRMS acts as boxes that predict the correct degrees of preparation for each thinking step, which requires wide -ranging comments at the step level. Verify the generated PRMS framework as a task to eloquent the language, which leads to right decisions as a natural language symbol accompanied by the thinking chain (COT). These models are calculated correct degrees through conditional symbolic possibilities such as P (“correct”), which makes them interpretable and subject to their nature. Improved scaling techniques at the time of testing, such as the best choice of N and tree -based search, thinking using an additional conclusion time account. The effectiveness of these methods depends greatly on the quality of verification to record solutions.
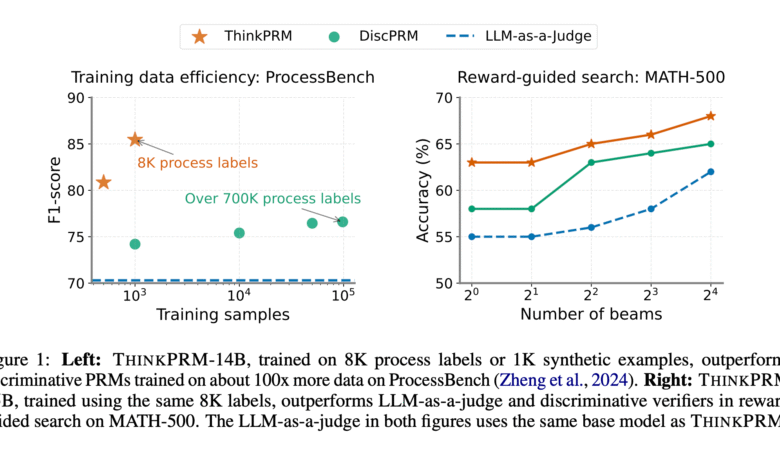
Researchers from the University of Michigan, Mila, LG AI Research, and Illinois Urbana Champrm University, which is a long -wicked Children, has been seized on a much lower practical stickers than those required by discriminatory PRMS. It uses the inherent thinking capabilities of the long COT models to excel both LLM-AS-A-Dugy and the Distinguished Veariers with the use of only 1 % of practical stickers in PRM800K via many difficult standards. In light of the equal code budgets, Vitchprm Scales calculate more effectively from LLM-AS-A-Judge, 7.2 % excels over a sub-range of the operating table, highlighting the long prlom value to expand the test time test with minimal supervision.
ThinkPrm is evaluated versus DISPRM, which is the same as the main model that was moved with a dual input on the entire PRM800K data collection that contains 712 kg for 98K problem -solving pairs. Additional comparisons include unwanted majority and the most likely to verify the best experiences. Results are shown in three mathematics tasks: 100 Math-500 problems that cover all levels of difficulty, 2024 American propaganda mathematics exam (AIME), duties outside the field including GPQA-Diamond physics and a 200 Problem sub-group of LiveCodebeench V5. For Math-500, researchers used ThinkPrm-1.5B and ThinkPrm-14B with two different models of the generator.
On the best choice of N with Math500, ThinkPrm achieves higher or comparable thinking accuracy to ignore all samples budgets. Under the directed search on the Math-500, ThinkPrm-1.5B excels over Disprm by approximately 5 degrees Celsius and bypassing LLM-AS-A-Judge using the same basic model (R1-SWEN-1.5B). The THINKPRM-1.5B scalp curve exceeds all the foundation lines when compared to powerful PRMS such as RLHFLOWOW-DeepSeek-PRM and Math-SHEPHERD-PRM, surpassing RLHFLOWOW-Deepsek-PRM by more than 7 % in 16 packages. For evaluation outside the field, ThinkPrm shows a better scaling than Disprm on GPQA-Pehyics, exceeding 8 %, while in LiveCodebench, ThinkPrm Disprm exceeds 4.5 %.
In conclusion, researchers, ThinkPrm, which is the model of the triggered obstetric process with the minimum supervision of artificial data, allows effective and developing effective verification of step -by -step. Researchers show that the light control of the obstetric banking on a fewer 8K practical stickers can improve the LLM-AA-A-Dugy yellow lines. ThinkPrm also outperforms the PRMS discrimination trained by orders from the most large signs, highlighting the advantages of using the Obstetrics TVs’ goals for interpretation, expansion and data efficiency. Results emphasize the Obstetical PRMS capabilities to expand the scope of checking at the time of testing effectively, and to take advantage of difficult areas such as sports and scientific thinking.
verify paper. Also, do not forget to follow us twitter And join us Telegram channel and LinkedIn GrOup. Don’t forget to join 90k+ ml subreddit.
🔥 [Register Now] The virtual Minicon Conference on Agency AI: Free Registration + attendance Certificate + 4 hours short (May 21, 9 am- Pacific time)

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-04-29 17:40:00



