This AI Paper Introduces ARM and Ada-GRPO: Adaptive Reasoning Models for Efficient and Scalable Problem-Solving
Thinking tasks are an essential aspect of artificial intelligence, and include areas such as understanding of participation, solving mathematical problems, and symbolic thinking. These tasks often include multiple steps of logical reasoning, which are attempts to imitate large linguistic models (COT). However, as LLMS grows in size and complexity, it tends to produce longer outputs in all tasks, regardless of difficulty, which leads to great inefficiency. The field was seeking to balance the depth of thinking with the computational cost while ensuring that models could adapt its thinking strategies to meet the unique needs of each problem.
There is a major problem in current thinking models, which is the inability to adapt the thinking process to the complexities of different tasks. Most models, including well-known models such as Openai’s O1 and Deepseek-R1, are applied, a unified strategy-highly dependent on the long cradle in all tasks. This causes the problem of “thinking”, as models generate unnecessary prolonged interpretations of simpler tasks. Not only is these waste resources, but it also degrades accuracy, because excessive thinking can provide non -relevant information. I have tried methods such as directed estimate or estimating the distinctive symbol budget to alleviate this problem. However, these methods are limited due to their dependence on pre -defined assumptions, which are not always reliable for various tasks.
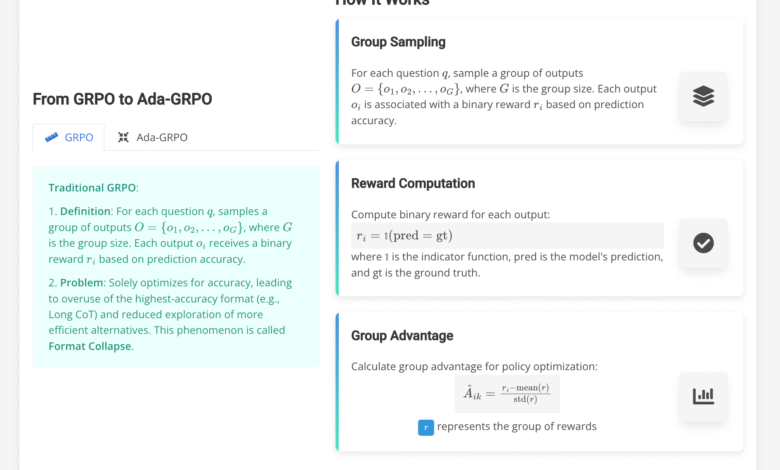
Attempts to address these problems include ways such as GRPO (improving the group’s relative policy), length mechanisms, and control control controls. Although GRPO enables models to learn different thinking strategies through the proper reward rewards, they lead to “coordination collapse”, where models are increasingly dependent on the long length bed, or more effective congestion, such as short bed or direct answer. Length techniques, such as those applied in methods such as ThinkPrune, the length of the direct control during training or inference, but often at the expense of low accuracy, especially in the tasks of solving complex problems. These solutions are struggled to achieve a fixed comparison between the effectiveness of logic and efficiency, which highlights the need for an adaptive approach.
A team of researchers from the University of Vodan and Ohio University presented the ARM model, which dynamically adjusts thinking formats based on the difficulty of the task. ARM supports four distinctive thinking patterns: the direct answer to simple tasks, short Cot for brief thinking, a symbol of organized problems solving, and long begging for deep -step deep thinking. It operates in the air conditioning mode, identifying the appropriate format automatically, also provides situations directed to consensus and directs unanimity for explicit control or assembly through formats. The main innovation lies in the training process, which uses Ada-GrPo, an extension of GRPO that provides a variety of diversity bonus mechanism. This prevents the dominance of the long cradle and ensures that his arm continues to explore and use the most simple thinking formats when necessary.
The arm methodology was built on a two -stage frame. First, the SFT model (SFT) is subject to 10.8K questions, each of which is explained through four thinking formats, obtained from data sets such as Aqua periods and the creation of tools such as GPT-4O and Deepseek-R1. This stage teaches the model with the structure of all the coordination of thinking, but it does not instill the ability to adapt. The second stage is ADA-GRPO, where the model receives size bonuses for the use of less frequent formats, such as direct answer or short COT. The decomposition factor guarantees that this reward gradually turns into accuracy with the progress of training, which prevents long -term bias towards ineffective exploration. This ARM structure enables to avoid the collapse of coordination and identifies the dynamic thinking strategies for the difficulty of the task, and a balance between efficiency and performance.
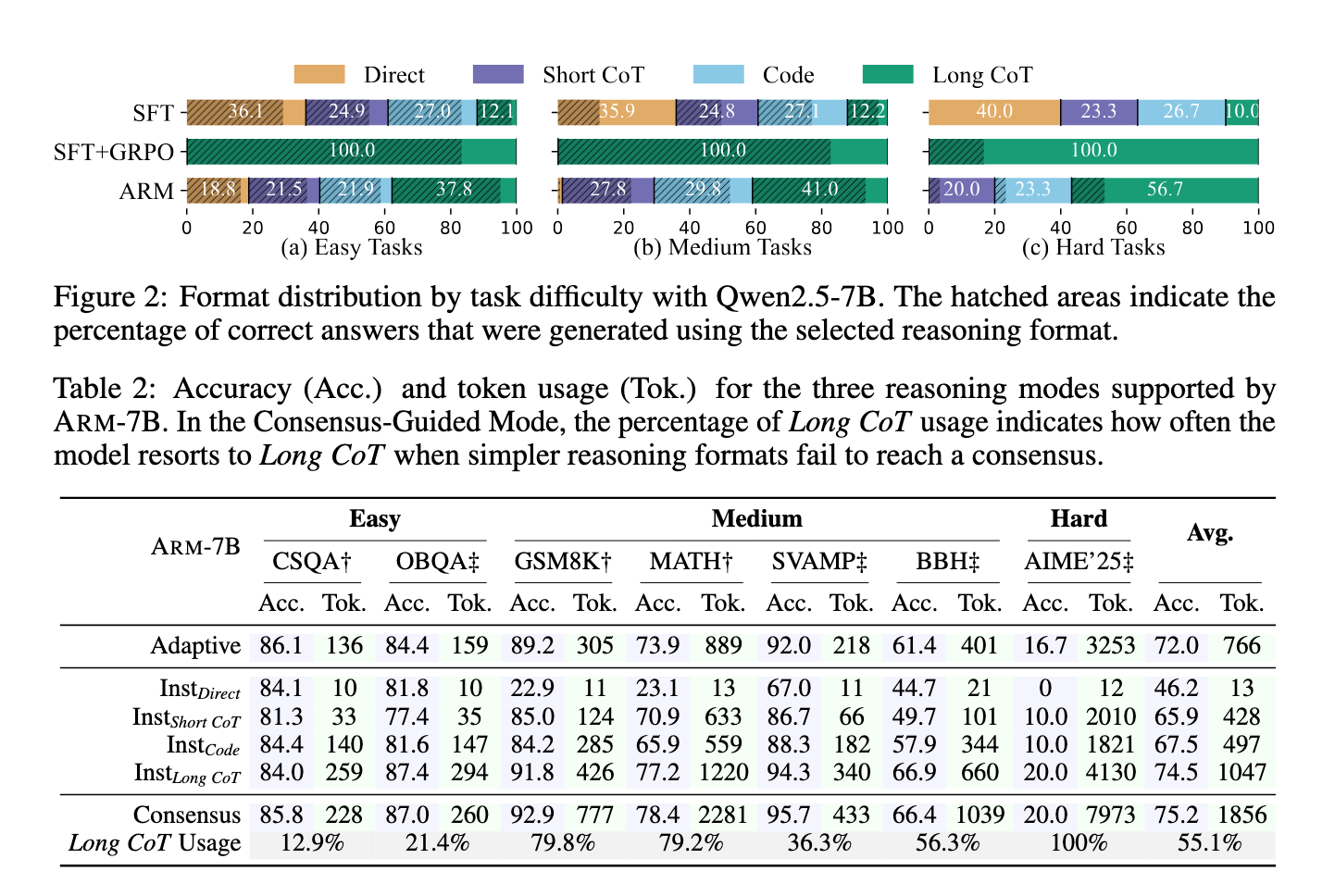
ARM has shown impressive results across various criteria, including logical, sports and symbolic thinking tasks. It has reduced the use of a 30 % distinctive symbol on average, with discounts of up to 70 % for the simplest tasks, compared to models that depend only on the long cradle. ARM has accelerated 2x training on GRPO models, which faster developing the model without sacrificing accuracy. For example, ARM-7B has made 75.9 % resolution on the difficult AIME’25 mission with 32.5 % lower codes. The ARM-14B achieved 85.6 % accuracy on OpenBookqa and 86.4 % on the mathematics data set, with a reduction in the use of the distinctive symbol for more than 30 % compared to QWEN2.5Sff+GRPO models. These numbers show ARM’s ability to maintain competitive performance while achieving great efficiency gains.
In general, the adaptive thinking model addresses the constant efficiency of thinking models by enabling the adaptive choice of thinking formats based on the difficulty of the task. Enter Ada-GRPO and a multi-coordination training framework ensures that models no longer waste resources to think about thinking. Instead, ARM provides a flexible and practical solution to a balance between accuracy and mathematical cost in thinking tasks, which makes it a promising approach to the large, developed and effective language models.
Check the paper, models on the embrace and project page. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 95K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-31 08:18:00