Amazon introduces AI agent to do your online shopping for you, almost Amazon’s AI agent will make it even easier for you to part with your money
The next big thing in the field of artificial intelligence is the Agentic AI, which is mainly an Amnesty International tool that can automate multi -steps for users. For example, interacting with a web browser for tasks such as booking tickets or grocery order.
Amazon definitely sees a future there. After providing a tremendous reform to Alexa and introducing a new Alexa+ assistant, the company announced today a new agent for Amnesty International called Nova Act. Amazon says Act Nova is designed to “complete the tasks in the web browser.” Amazon will not be the first to reach this teacher, as other artificial intelligence companies have already tried this vision.
]
The Openai operator is designed to deal with the frequent and worldly parts of the web browsing on behalf of users, such as filling models or submitting applications online. People behind the Opera browser also build an operator who can withdraw something similar using the natural language orders provided by users.
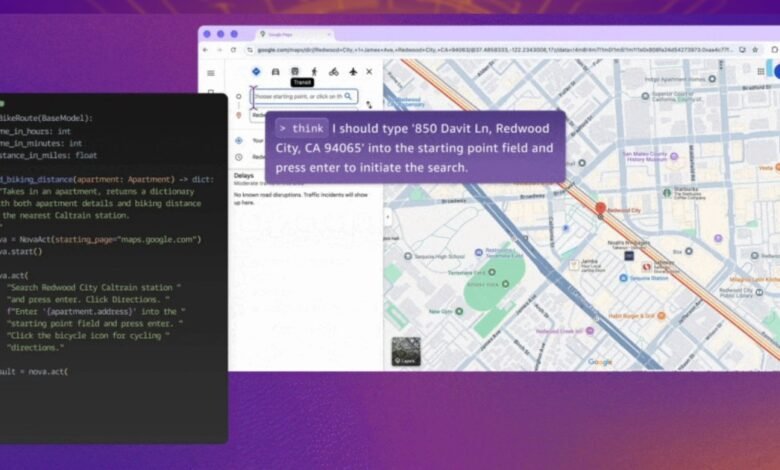
In the case of Amazon, the AIC AI NOVA agent was built on the summit of Nova, the company’s portfolio of Amnesty International models that were announced a few months ago. Multi -steps workflow can be divided into smaller inputs, such as conducting a search, adding elements, examining, or answering questions based on the activity on the screen.
Depending on the interior tests, the Amazon Agency Ai is described to perform better than the competing products from Openai and Anthropic. The company says it is looking for a level of accuracy of more than 90 %, especially in the browser -based tasks, as artificial intelligence tools often fail, such as popup, drop -down reactions, and dates.
]
NOVA is currently in the research inspection stage and was presented to developers. The company says: “Our dream is for the agents to perform widely complex, complex and multifaceted tasks such as organizing a wedding or processing the IT complex to increase work productivity.”
Interestingly, the foundations of Nova law have already been integrated into the framework of Alexa+. The virtual assistant is allowed to browse the web on behalf of users and accomplish homework. This is an enormous bonus of Amazon when it comes to reaching an audience of ACT Nova.
Access to Alexa+ is currently limited to the main subscribers or those who want to pay a monthly fee for the next generation assistant. Unlike Openai’s price agent, Amazon has a much larger audience sitting with the right devices at home to experience Alexa+ and ACT capacity.
trends"/>
2025-03-31 16:11:00