TwinMind Introduces Ear-3 Model: A New Voice AI Model that Sets New Industry Records in Accuracy, Speaker Labeling, Languages and Price
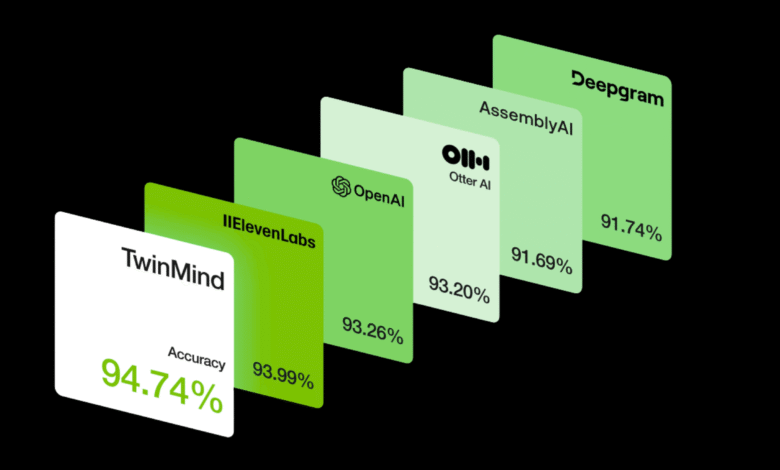
Twinmin, an artificial intelligence company based in California, unveiled it Ear-3 Speech recognition model, calling for modern performance on many main standards and extended multi -language support. The EAR-3 version is placed as competitive offers against ASR solutions (automatic speech recognition) of service providers such as DeepGRAM, Assemblyai, Eleven Labs, OTER, CounterMatics and Openai.
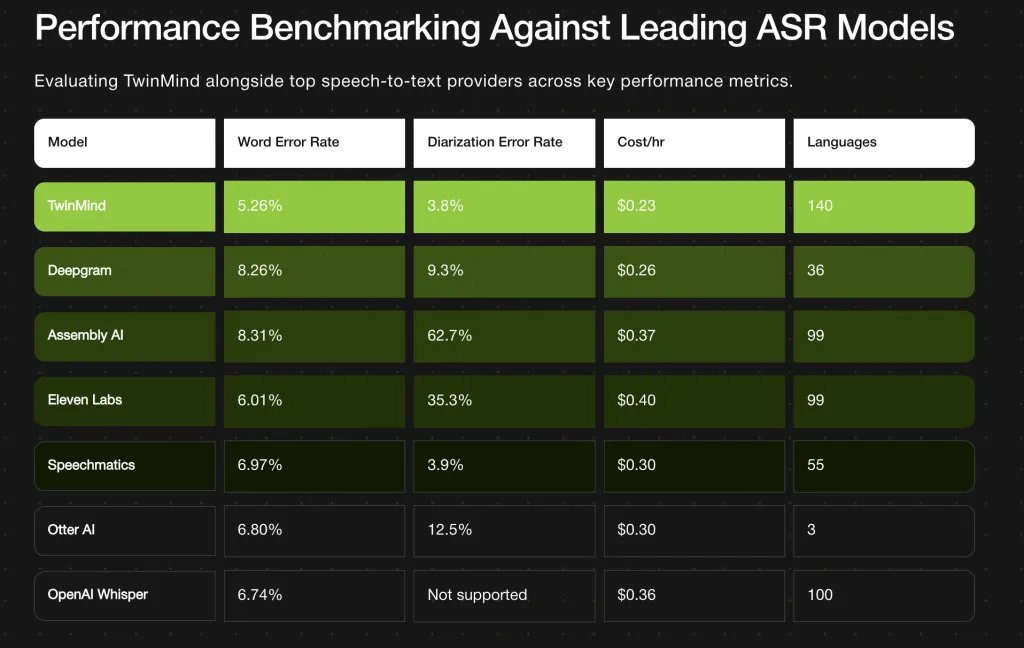
Main standards
| metric | Twinmin ear-3 result | Comparisons / notes |
|---|---|---|
| Word error rate (WE) | 5.26 % | Many less than competitors: DeepGram ~ 8.26 %, Assemblyai ~ 8.31 %. |
| DER Memoirs March | 3.8 % | A slight improvement on the best previous speech (about 3.9 %). |
| Language Support | 140+ language | More than 40 languages are more than many leading models; It aims to “real global coverage”. |
| The cost of copying per hour | 0.23 US/hour | Less placed between the main services. |
Technical approach and location
- Twinmind notes that Ear-3 is a “accurate mixture of several open source models”, trained on a set of coordinated data containing audio sources such as podcasts, videos and movies.
- Diarrhea and signs are improved by loudspeakers via a pipeline that includes sound cleaning and reinforcing it before diarrhea, as well as “accurate alignment verification” to improve headphone border discoveries.
- The model undertakes to switching code and mixed textual programs, which are usually difficult for ASR systems due to various audio, contrasting tone, and linguistic overlap.
Operational differentials and details
- Ear-3 It requires cloud publishing. Due to the size of his model and carrying his account, it cannot be completely not connected. TWINMIND’s EAR-2 (its previous model) remains a return back when the connection is lost.
- Privacy: TwinMind claims have not been stored in the long run; The texts are stored only locally, with optional encoded backup copies. The audio recordings “on flying” are deleted.
- Integration of the Basic System: The API is planned for the model in the coming weeks of developers/institutions. For final users, Ear-3 jobs will be presented to iPhone, Android, Chrome and Chrome applications next month for professional users.
Comparative analysis and consequences
Wer-3 scales were laid in Ear-3 before many models. Lome Wer translates into less than copy errors (wrong recognition, fallen words, etc.), which is very important to fields such as legal or medical copies, lectures or sensitive content archive. Likewise, Der der (IE is the best speaker + signs of meetings, interviews, and podcasts – anything with many participants.
The price point of $ 0.23/h makes high -resolution copies more clearly clearly for long -shape sound (for example hours of meetings, lectures and recordings). In conjunction with support for more than 140 languages, there is a clear boost to make it useful in global settings, not only the contexts of the English language or well.
However, cloud dependency can serve as restrictions for users who need no internet or device capabilities, or when data / access / access time concerns are strict. The complexity of implementation may be revealed to support more than 140 languages (tone erosion, dialects, code replacement) weaker areas under harmful sound conditions. Performance in the real world may vary compared to controlled standards.
conclusion
The TwinMIND’s Ear-3 model represents a strong technical claim: high resolution, the resolution of the speaker’s notes, wide linguistic coverage, and the reduction of aggressive costs. If the standards are possible to use, this may lead to converting expectations to what “distinct” copies should be provided.
verify Project page. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.

Michal Susttter is a data science specialist with a master’s degree in Data Science from the University of Badova. With a solid foundation in statistical analysis, automatic learning, and data engineering, Michal is superior to converting complex data groups into implementable visions.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-09-11 21:37:00