
Transformers Can Now Predict Spreadsheet Cells without Fine-Tuning: Researchers Introduce TabPFN Trained on 100 Million Synthetic Datasets
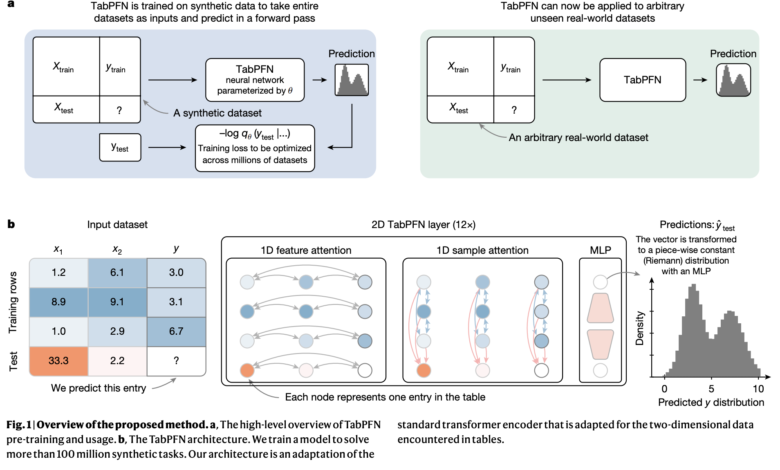
Table data is widely used in various fields, including scientific research, financing and health care. Traditionally, automatic learning models such as decision -making trees are preferred to reinforce the analysis of tabular data due to their effectiveness in dealing with heterogeneous and structural data groups. Despite its popularity, these methods have noticeable restrictions, especially in terms of performance on invisible data distributions, the transfer of knowledge learned between data groups, and the challenges of integration with models based on the nerve network due to their unconceptions.
Researchers from the University of Freiburg, the Institute of Health in Berlin, previous laboratories, and the Ellis Institute presented a new approach called a crazy, prepaid network (Tabpfn). Tabpfn is strengthening the transformer structure to treat common restrictions associated with traditional tabular data. The model greatly outperforms the decision -making trees enhanced by education in both classification and slope tasks, especially on data groups that contain less than 10,000 samples. It is worth noting that Tabpfn clarifies a noticeable efficiency, as it achieved better results in a few seconds compared to several hours of controlling the comprehensive superior required by the tree models based on the group.
Tabfn uses learning within the context (ICL), a technique that was initially presented by large language models, where the model learns to solve tasks based on the contextual examples provided during reasoning. The researchers adapted this concept specifically for tabular data by training before training in millions of data created industrial. This training method allows the model to implicitly learning a wide range of predictive algorithms, which reduces the need for wide training in the data set. Unlike traditional deep learning models, TabFN processes the entire data groups simultaneously during one pass through the network, which greatly enhances mathematical efficiency.
Tabpfn’s structure is specifically designed for tabular data, using a two -dimensional interest mechanism designed to use the effective tables that are effective. This mechanism allows each data cell to interact with others across rows and columns, and to manage different types of data and their conditions effectively such as factional variables, lost data and extremist residence. Moreover, TabPFN improves mathematical efficiency by storing intermediate representations from the training group, which is greatly accelerated in subsequent test samples.
Experimental assessments highlight the significant improvements to TABFN on existing models. Through various standard data collections, including Automl Benchmark and OpenML-STR23, TabPFN is constantly higher than models used widely such as XGBOOST, Catbook and Lightgbm. For classification problems, Tabpfn has shown noticeable gains in the usual ROC AUC degrees for the widely seized foundation line methods. Likewise, in the contexts of slope, it surpassed these applicable methods, as it displays the improved RMSE degrees.
Tabpfn’s durability has also been widely evaluated across data sets that are characterized by difficult conditions, such as many unrelated features, extremist values, and large missing data. Unlike model nervous network models, Tabpfn maintained a stable and stable performance in light of these difficult scenarios, indicating their suitability for practical applications in the real world.
Besides its predictive strengths, Tabpfn also displays the typical basic capabilities of basic models. It effectively generates realistic artificial scheduling data collections and accurately estimates the possibility of individual data points, which makes them suitable for tasks such as detection of homosexuality and increased data. In addition, the implications produced by the Tabpfn are meaningful and reusable, providing a practical value of the estuary tasks including assembly and verification.
In short, the development of tabfn indicates an important progress in tabular data modeling. By integrating the strengths of the transformer -based models with practical requirements for regulatory data analysis, TABFN provides reinforced accuracy, mathematical efficiency, durability, and may facilitate significant improvements across various scientific and commercial fields.
Here is paper. Also, do not forget to follow us twitter And join us Telegram channel and LinkedIn GrOup. Don’t forget to join 90k+ ml subreddit.
🔥 [Register Now] The virtual Minicon Conference on Agency AI: Free Registration + attendance Certificate + 4 hours short (May 21, 9 am- Pacific time)
SANA Hassan, consultant coach at Marktechpost and a double -class student in Iit Madras, is excited to apply technology and AI to face challenges in the real world. With great interest in solving practical problems, it brings a new perspective to the intersection of artificial intelligence and real life solutions.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-04-16 01:27:00



