
Researchers from the National University of Singapore Introduce ‘Thinkless,’ an Adaptive Framework that Reduces Unnecessary Reasoning by up to 90% Using DeGRPO
The effectiveness of the language models depends on its ability to simulate a step -by -style discount. However, these thinking sequences are dense resource and can be illuminated by simple questions that do not require a detailed account. This lack of awareness regarding the complexity of the mission is one of the basic challenges in these models. They are often virtual to detailed thinking even for inquiries that can be answered directly. Such an approach increases the use of the distinctive symbol, extends the time of response, increases the time of the system transmission and the use of memory. As a result, there is an urgent need to provide language models with a mechanism that allows them to make independent decisions about whether to think deeply or respond briefly.
Current tools that try to solve this problem depend on either manually evaluating or immediate engineering to switch between short and long responses. Some methods use separate models and guidance questions based on sophisticated estimates. However, these external guidance systems often lack an insightful look at the strengths of the target model and whisk in making optimal decisions. Other techniques raise models with “thinking/suspension” signals, but these depend on fixed rules rather than dynamic understanding. Despite some improvements, these methods fail to enable full independent and sensitive context within one model.
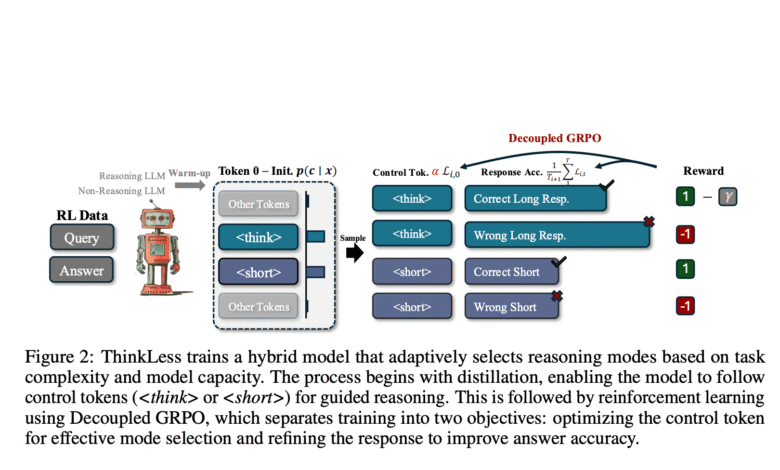
Researchers from the National University of Singapore presented a new framework called Thinkless, which provides a language model with the ability to make a dynamic decision between using short or long -form thinking. The frame is based on reinforcement learning and offers two distinctive symbols to control –
The methodology includes two phases: warm -up and reinforcement learning. In the distillation stage, without thinking is trained using outputs of two experts – one specializing in short responses and the other in detailed thinking. This stage helps to create a fixed link between the control code and the desired thinking format. The reinforced learning stage, then form the model’s ability to determine the thinking mode that must be used. DeGRPO The learning decomposes into two separate goals: one to train the control code and the other to improve response symbols. This approach avoids gradual imbalances in previous models, as long responses overcame the learning signal, which leads to a collapse in the diversity of thinking. Do not think about it both
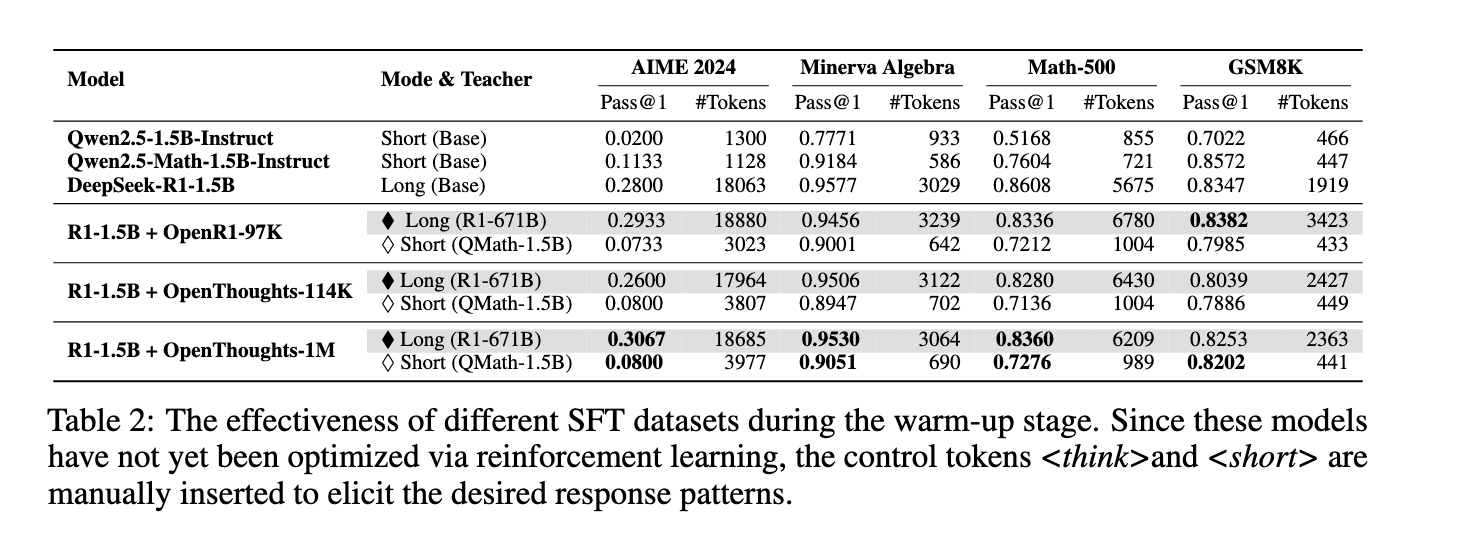
Upon evaluation, the thought dramatically reduced long thinking while maintaining high accuracy. On the Mineeva Algebra standard, use the form
In general, this study of researchers at the National University of Singapore provides a convincing solution for uniform thinking in large language models. By introducing a mechanism that enables the models to judge the complexity of the task and control their inference strategy accordingly, there is no doubt coordinating both accuracy and efficiency. The method works to balance the depth of thinking and the accuracy of response without relying on fixed rules, which provides a data -based approach to the most intelligent language model behavior.
Check the paper page and GitHub. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 95K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.

Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-05-23 05:59:00



