
Can a Small Language Model Predict Kernel Latency, Memory, and Model Accuracy from Code? A New Regression Language Model (RLM) Says Yes

Researchers from Cornell and Google presents the RLM language model that predicts the digital results directly from the code chains-which increases the time of Kerneel GPU, the use of the program’s memory, and even the accuracy of the nervous and technical network-without hand-protected features. The Bermezer Cheer 300 meters from T5 -GMA is a strong connection to the classification via tasks and heterogeneous languages, using one coding unit to a number of text from which numbers are emitted with restricted decoding.
What is the exact new?
- Slope with a unified symbolOne of the RLM (I) peak memory of the high-level code (Python/C/C ++), (II) (II) Time for GPU TRITON, and (III) accuracy and cumin for devices from ONNX graphs by reading raw raw text representations. Feature engineering, graphic symbols, or zero cost agents.
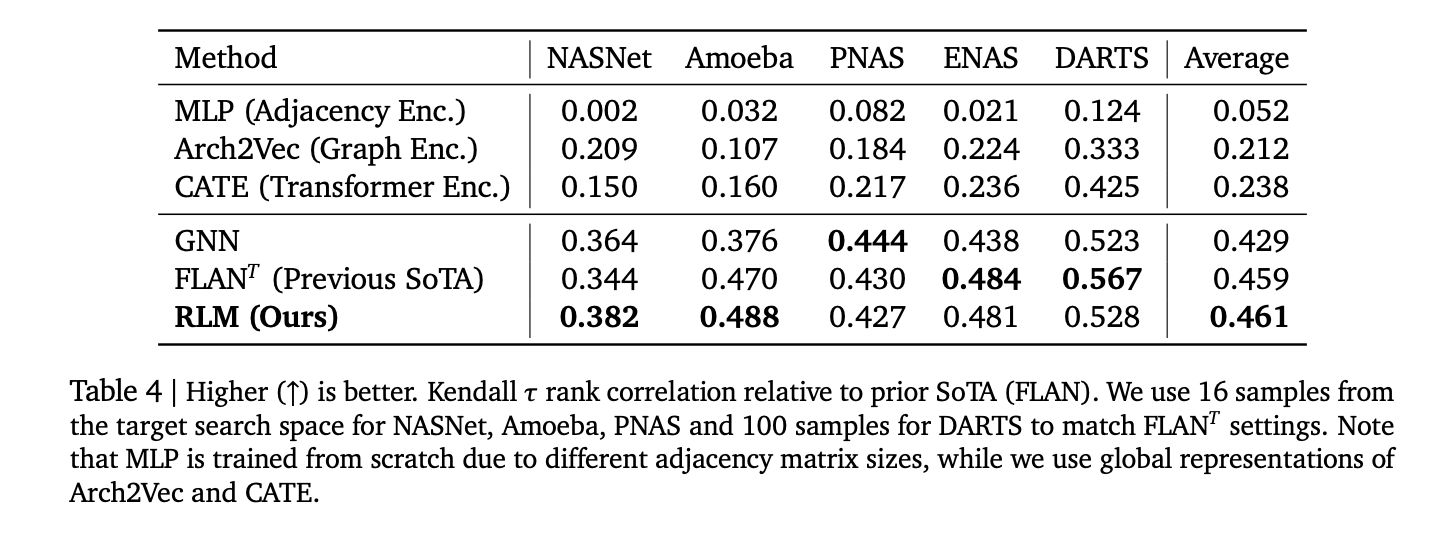
- Concrete: The links are reported Spearman ρ 0.93 On Apps Leetcode applications, ρ ≈ 0.52 To connect Triton Kerneel, ρ> 0.5 Mediterranean across 17 languages codnetAnd Kendall τ 0.46 Through five classic NAS-competitive spaces with and outperforms some of the cases based on the graph.
- Decoding multi -targets: Since the unit of coding is automatic, the typical conditions later are standards over those previous (for example, the accuracy of → time of banana for each device), and capturing realistic bodies along the Barito fronts.

Why is this important?
Performance prediction tubes depend on translators, the choice of the GPU nucleus, and NAS usually on detailed features, sentences or GNN codes that are fragile to OPS/new languages. Treatment of slope as The next prediction of the numbers Standardization of the stack: the input code as an ordinary text (source code, Titon IR, onnx), then deciphering the numerically calibration digital chains with restricted samples. This reduces the cost of maintenance and improves transportation to new tasks through control.
Data and standards
- Code Data set (HF): Under the auspices of support Code to Metrick The tasks that extend on/leetcode applications, Triton Kernel Cynelies (Kernelbook -By-SHIIVED), and the effects of Codenet memory.
- NAS/ONNX SuiteNasbench-101/201, FBNET, once for everything (mb/pn/r) ONNX text To predict the accuracy and cumin of the device.
How do you work?
- vertebral column: Coding – coding with a T5 -Gmama Cooking encryption (~ 300m PARAMS). Inputs are primary chains (symbol or ONNX). Outputs are numbers that are emitted Mark/prices/Mantisa numbers; Restricted decoding imposes good numbers and supports uncertainty by sampling.
- Meals: (I) the language before you accelerate the rapprochement and improve the prediction of TRITON; (the second) Digital emissions only decipher transparency It surpasses the heads of slope mse even with Y-Nordization; (3) The specialized features of ONNX operators increase the effective context; (4) It helps longer contexts; (5) Large gemma coding improves the link with adequate control.
- Training code. the LM retreat The library provides textual decline facilities to the text, restricted coding, and multi -tasking recipes/refining them.
Statistics of concern
- Python Applications: spearman ρ> 0.9.
- Codenet (17 languages) Memory: middle ρ> 0.5; It includes the most powerful C/C ++ (~ 0.74 -75).
- Triton Kernels (A6000) Cumin: ρ ≈ 0.52.
- NAS Classification: middle Kendall τ 0.46 Via Nasnet, Amoeba, PNAS, Enas, Arrows; Competitive with FAN and GNN foundation.
Main meals
- The code decline to the unified artery. One model ~ 300M-PARMERETER T5GEMAA-Initialized (“RLM”):
- Spearman’s search appears> 0.9 on applications memory, ≈0.52 on TRION transition time,> 0.5 average across 17 Codenet languages, and Kendall-≈ 0.46 over five nas.
- The numbers are decoded as a text with restrictions. Instead of the head of slope, RLM emites digital symbols with restricted decoding, allowing multi -measurement, automatic (for example, accuracy followed by multi -device time) and uncertainty through sampling.
- the The spread of the code The data collection unifies the Apps/leetcode memory, Titon Kernel Cumin, and Codenet memory; the LM retreat The library provides a staple training/decoding.
It is extremely interesting how this work restores performance as a text generation to number: T5Gemma-initialized Read (Python/C ++), Triton nucleus, or onnx charts and calibration numbers through restricted transplantation. The connections are reported-Apps (ρ> 0.9), TRITON Cumin on RTX A6000 (~ 0.52), NAS Kendall-≈0.46- Strong enough for what is important to resignation translations, kirnil trim, and multi-cold NAS or GNNS. The open data collection and the library make the symmetrical copies clear and reduce the barrier to refining new devices or languages.
🚨 [Recommended Read] VIPE (Video Engine): A powerful and multi -dimensional 3D video explanation tool
verify paperJaytap page and Data set card. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter. I am waiting! Are you on a telegram? Now you can join us on Telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically intact and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
🙌 Follow Marktechpost: We added as a favorite source on Google.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-10-04 05:58:00



