Adobe Research Unlocking Long-Term Memory in Video World Models with State-Space Models

Global video models, which expect future frameworks on the procedures, hold a tremendous promise of artificial intelligence, enabling agents to plan and cause dynamic environments. Recent developments, especially with video publishing models, have shown impressive potential in generating realistic future sequences. However, the bottle neck remains big: Memorize memory in the long run. The current models are struggled to remember events and countries from the past due to the high calculations associated with the processing of expanded sequences using traditional attention layers. This limits their ability to perform complex tasks that require a constant understanding of the scene.
A new paper proposes, “The Long World Space Models of government Space” by researchers from Stanford University, Princeton University, and Dubai Research, an innovative solution for this challenge. They offer a new structure that benefits State area models (SSMS) To expand time memory without sacrificing mathematical efficiency.
The main problem lies in the rhetoric complication of attention mechanisms in terms of sequence. With the growth of the video context, the resources needed for attention layers explode, which makes the long -term memory inappropriate for realistic applications. This means that after a certain number of tires, the model “actually” the previous events, which hinders its performance in tasks that require long -term cohesion or thinking over the extended periods.
The main insight of the authors is to take advantage of the strengths in the government space models (SSMS) for the mixture of the causal sequence. Unlike previous SSMS attempts to restart unproductive vision tasks, this work exploits its entire advantages in treating sequences efficiently.
Proposal Long Space Context Model (LSSVWM) It includes many decisive design options:
- SSM wise scanning chart: This is essential to their design. Instead of processing the entire video sequence with one SSM examination, they use a wise scheme. This strategically trades some spatial consistency (within a mass) of the largely extended time memory. By dividing the long sequence into controlled blocks, they can maintain a compact “state” that carries information across the blocks, which effectively expands the memory of the model.
- Heavy local interest: To compensate for the potential loss of spatial cohesion made by the wise SSM scanner, the model includes heavy local interest. This ensures that the successive tires inside the blocs and through them maintain strong relationships, while maintaining the fine details and consistency needed to generate realistic video. This double -processing approach to global treatment (SSM) and local treatment (attention) allows them to achieve long -term memory and local devotion.
The paper also provides two main training strategies to increase the improvement of long context’s performance:
- Forcing spread: This technology encourages the model to create conditional tires with height of the inputs, forcing it effectively to learn to maintain consistency at longer periods. By not taking samples of prefabs at times and maintaining all the distinctive symbols, the training becomes equivalent to the effect on spreading, which is highlighted as a special case for training on the long text where the height is zero. This drives the model to generate a coherent sequence even from the minimum of the initial context.
- Local interest framework: To train faster and take samples, the authors have carried out a “local framework for attention” mechanism. This uses Flexatttenation to achieve large speeds compared to a full causal mask. By collecting tires into parts (for example, cut 5 with the size of the frame window 10), the tires keep inside a piece on the two -way as they are also present to the tires in the previous part. This allows an effective accepted field while improving the arithmetic load.

The researchers evaluated LSSVWM on difficult data collections, including Memory maze and MinecraftWhich is specially designed to test the long -term memory possibilities through retrieval tasks and spatial thinking.
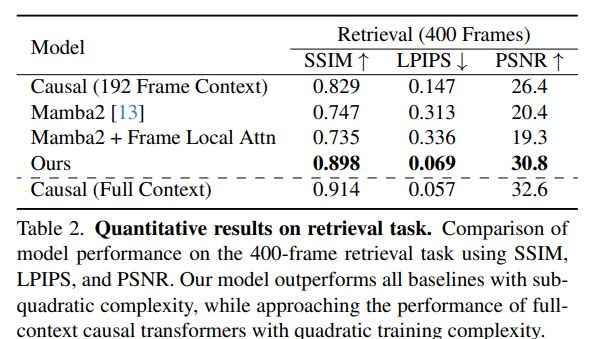
Experiments show that their approach It greatly outperforms the foundation lines In maintaining long -term memory. The qualitative results, as shown in supplementary numbers (for example, S1, S2, S3), show that LSSVWM can generate more cohesive and accurate sequences over the extended periods compared to models that depend only on causal interest or even mamba2 without a local framework. For example, in thinking tasks for the MAZE data group, its model maintains better consistency and accuracy on long horizons. Likewise, for retrieval tasks, LSSVWM appears to be improved to summon information and benefit from previous tires. Decally, these improvements are achieved while maintaining practical reasoning speeds, making models suitable for interactive applications.
Paper World models for the long space of space It is on arxiv
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-28 09:31:00