New AI Method From Meta and NYU Boosts LLM Alignment Using Semi-Online Reinforcement Learning

Improving LLMS to align man with reinforcement learning
Large language models often require another alignment stage to improve human use. At this stage, learning to reinforce a major role by enabling models to make decisions based on human comments or task -based right. This precise control of the specifications allows to align more closely with the user’s expectations, making them more suitable for applications based on accurate mathematical instructions or tasks.
Challenges in choosing learning strategies online reinforcement for the Internet
Great difficulty arises when choosing the most effective way to make this adjustment. Training methods are located in extremist approaches-linear approaches that depend on pre-established data and full online curricula that are constantly updated with each new interaction. Each way has distinctive challenges. The models that are not connected to adaptation during training, which limit performance, can not often require more mathematical resources. Moreover, ensuring that the models work well through both sports (that can be verified) and open (uncompromising) that adds more complexity to this choice.
Overview of algorithms algorithms: DPO and GRPO
Historically, tools such as improved direct preference (DPO) have been used and the Group’s relative policy improves to align the model. DPO operates without an internet connection and is designed to work with preference -based data pairs. It is estimated to extend it and data efficiency, but it lacks the ability to adapt to online methods. GRPO depends on the PPO algorithm and treats polishing online by comparing the output groups to calculate the relative advantages. While GRPO adapts in actual time and is suitable for dynamic reward systems, its nature of quality increases the arithmetic pregnancy and makes the experience more demanding.
A balanced alternative to align llm
The research entered by Meta and NYU explored a way to overcome these restrictions by preparing semi -initial training. This technology modifies the frequency of the components of the generation of the model and training, rather than updating in each training step, as in the entire online methods, or not at all, as in the settings that are not connected to the Internet. The method of semi -terrestrial lines is raised by controlling the synchronization rate. The researchers designed this approach to reduce training time and maintain high -forming ability. The normative preparation also allowed them to apply either DPO or GRPO with a flexible bonus reward.
Next education and sports thinking
The methodology included the formulation of the Llama-3.1-8B-Instruct model using two types of tasks: the following open instructions and problem solving in mathematics. For non-executable tasks, samples of the user’s claims were taken from the Wildchat-1M data collection and evaluated using the ATHENE-RM-8B bonus form, which helps the numerical degrees of each router. For verified tasks, the team used the Numinamath Data Data set in conjunction with the Math-Velify Tools collection, which is realized whether the answers created are in line with expected outputs. Training experiments were conducted on 32 NVIDIA H22 graphics processing units and 8 graphics processing units for reasoning, with various settings comparing periods of synchronization that is not connected to the Internet and semi -linear.
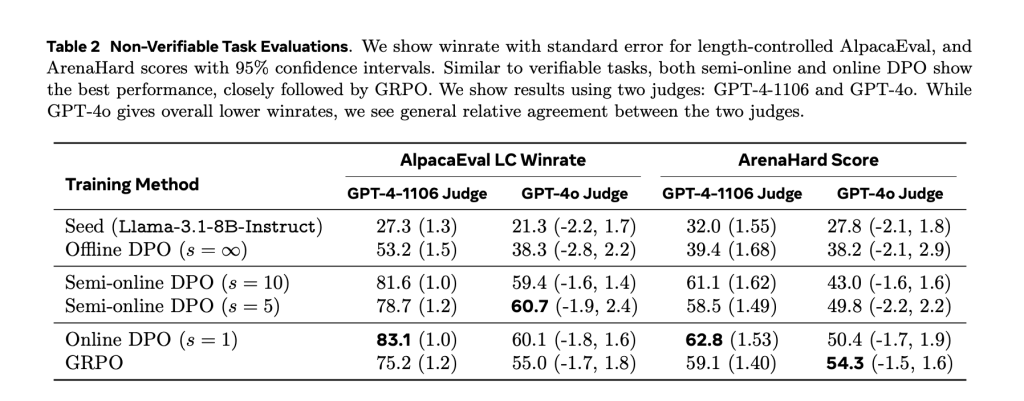
Performance gains via all of the verified and non -verified tasks
Performance differences have been observed. In Math500, DPO without an internet connection arrived 53.7 %, while DPO is almost on a line with a synchronous separator of S = 100 achieved 58.9 %. DPO and GRPO online showed similar results at 58.7 % and 58.1 %, respectively. Similar trends have been observed on the Numinamath standard, where DPO without contact achieved 36.4 %, and this semi -linear variables increased to 39.4 % (S = 10). Performance gains are not limited to mathematics tasks. When implemented tasks were evaluated with Albakifal 2.0 and ARNA hardMs standards, trained models with mixed bonuses that are done better constantly. The combination of verified and non -verified bonuses led to the preparation of one training to average stronger degrees, indicating that the method is effective.

Flexible and developed approach to learning reinforcement in LLMS
This study shows that the formulation of large language models does not require strict commitment to the settings that are not connected to the Internet or online. By entering a flexible coincidence scheme, the research team from Meta and NYU effectively increased the efficiency of training while maintaining or improving performance. The results show that the budget of the types of rewards and the frequency of the training synchronization carefully leads to models that work well through the types of tasks without incurring high mathematical costs.
verify paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitterand YouTube and Spotify And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-06 22:05:00